1. Introduction
Soil is a vital part of our planet, comprising 25% air, 25% water, and the remaining 50% being a mix of organic and inorganic materials [1]. This soil offers us essential services, from food and fuel to building materials, supporting both our health and ecosystems [2]. However, mining and manufacturing industries are rising as major causes of soil pollution, which is becoming a big issue [2, 3]. Contaminated soils pose risks to both ecology and human health, intensifying the need for effective methods to identify and track such pollution [4–7]. Moreover, the leakage of chemicals can change the soil’s pH and other important features, highlighting the need for studies on these effects and urgent soil protection efforts [8–10].
Bacterial communities within soil are crucial for maintaining its health and functionality [11–13]. These changes in the soil bacterial community can be seen as sensitive indicators of environmental changes and contamination events [14, 15]. Specifically, Proteobacteria play key roles in environmental processes like nitrogen fixation [12], while Firmicutes are known to be active even in certain acidic conditions [14, 16]. Analyzing the structure of these bacterial communities can serve as an essential tool for understanding and addressing soil contamination. Terminal restriction fragment length polymorphism (T-RFLP) stands out as a cost-effective technique useful for assessing such bacterial diversity, offering a concise depiction of bacterial classifications [17, 18]. Therefore, a detailed analysis of bacterial communities plays a significant role in evaluating soil’s environmental health and contamination status.
Soil pollution, particularly acid contamination, arises from various sources and negatively affects the environment. In a previous report, numerous factors, including industrial accidents, have been pinpointed as leading causes of soil pollution in the industrial sector [2]. Chemical spills, fires, and explosions can result in major disasters for residents and the environment, causing financial losses, raw material shortages, and severe disruptions across various industries [19–21]. HCl can easily induce soil and groundwater acidification [22, 23] while HNO3 reduces soil’s buffering capacity [24]. In addition, H2SO4 and HF cause soil expansion and rapidly dissolve plant silica, respectively [25]. Such acid leaks lead to environmental problems like a decrease in soil pH, resulting in shifts in soil bacterial communities, reduced crop yields, and respiratory diseases [4, 9, 26–28]. Considering these multifaceted causes and impacts, it is essential to accurately identify acid pollution sources.
Soil contamination is becoming increasingly complex, necessitating the use of modern technologies. Machine learning models, such as artificial neural networks (ANN), random forest (RF), support vector machines (SVM), and K-nearest neighbors (KNN), can be utilized in predicting acidic pollution sources [29–32]. Inspired by the structure of the human brain, ANN are capable of processing complex data information arising in genetics, such as the 16SrRNA gene of bacteria, enabling the prediction of relationships with acidic contaminants [29, 33, 34]. However, to enhance the accuracy of these predictions, a sufficient amount of data is required for training machine learning models. The introduction of generative adversarial networks (GAN) for data augmentation provides a solution to this challenge [35, 36]. In comparison to conventional machine learning, GAN can greatly refine the accuracy of identification of soil contaminants. In this study, it was hypothesized that machine learning models combined with tools like T-RFLP enhance the performance of forensics by generating diverse biological indicators of terminal restriction fragments (T-RFs) [17, 37–39]. Harnessing a blend of these advanced techniques and data methodologies holds great promise in addressing the challenges of soil pollution.
This study aims to develop a forensic tool for acidic pollution through T-RFLP analysis and machine learning. After introducing tap water, HCl, HF, HNO3, and H2SO4 to healthy soil, we investigated the temporal changes in bacterial communities using both T-RFLP and next-generation sequencing (NGS). The data obtained from T-RFLP was augmented using GAN. Then, using trained machine learning models, including SVM, KNN, RF, and ANN, we classified the samples based on the specific acidic pollutants. This novel forensic approach offers precise predictions and insights into the effects of various acidic contaminants on bacterial communities.
2. Materials and Methods
2.1. Simulated Acidic Pollutant Leakage
To simulate an acidic contaminant leak, 10 soil columns with a diameter of 5 cm and a length of 21 cm were filled with 550 g of soil (from 35°14′38.4″N 129°03′23.4″E). Subsequently, tap water (pH 7.01±0.1, conductivity 98±10 us/cm), 1.0 N HCl (Samcheon Chemical Co., Korea), HF (Duksan Pure Chemical Co., Korea), HNO3 (Samcheon Chemical Co., Korea), and H2SO4 (Junsei, Japan) were added to the five autoclaved soil columns in volumes equal to the soil. The same process was also performed on the five non-autoclaved soil columns with the same acidic contaminants. Leakage was conducted on days 1 and 3. From day 5 to 10, rain simulation was performed using an amount of tap water equivalent to the soil volume. Starting from day 10, this rain simulation was repeated every 5 days using tap water of the same specifications. In this manner, a total of 34 days were spent conducting leakage and rain simulations.
2.2. Sampling
From the soil column subjected to tap water and four types of acidic contaminant leakage, soil samples were collected on days 1 and 3 post-leakage, during the rain simulations from days 5 to 10, and on days 16, 22, and 28. Additional samples were also taken on days 19, 25, 31, and 34 when no treatments were applied. On days 1, 3, and the final day 34, samples were specifically collected from the top, middle, and bottom sections of the soil column, totaling 100 soil samples (Table S1).
2.3. pH Analysis
Each 2.5 g soil sample was mixed with 5 mL distilled water, agitated at 150 rpm, 25°C for 30 minutes, and its pH was measured using a pH probe (AB15+ Model, Thermo-Fisher Scientific, USA).
2.4. DNA Extraction
Soil samples for DNA extraction were collected from the soil column, amounting to 500 mg, and were stored at 20°C until DNA extraction. A total of 100 samples were collected, and sample codes are provided in Table S1. Genomic DNA was extracted using the SPINeasy DNA Kit for Feces/Soil (MP Biomedical, USA), and further purified with the DNeasy Power clean Pro Cleanup Kit (Qiagen, USA). The concentration of the extracted DNA was analyzed using the QubitTM 4 Fluorometer (Invitrogen, USA).
2.5. Next-Generation Sequencing
For the analysis of soil bacterial communities, Bacterial 16S rRNA gene amplicons (V3 and V4 regions) were sequenced on the Illumina MiSeq platform (Illumina, San Diego, CA, United States) by Macrogen Inc (Seoul, South of Korea). Post-sequencing, samples were categorized using index sequences, and paired-end FASTQ files were generated. Sequencing adapters and target gene region primers were removed with Cutadapt (v3.2). Amplicon sequencing was error-corrected using the DADA2 (v1.18.0) package in R (v4.0.3). Reads exceeding 2 expected errors were discarded, and sequences were truncated to 250 bp for Read1 and 200 bp for Read2. After establishing a batch-specific error model, noise was removed from samples. Corrected paired-end sequences were merged and chimeric sequences were removed using DADA2’s Consensus method to form ASVs. For microbial community comparisons, normalization was performed using QIIME (v1.9) based on the sample with the fewest reads. Each ASV was matched against the NCBI 16S Microbial DB using BLAST+(v2.9.0) to assign taxonomy, but assignments were skipped if query coverage or matched region identity was below 85%.
2.6. Terminal Restriction Fragment Length Polymorphism
The 16S rRNA gene was amplified for T-RFLP analysis using primers 27F and 518R [40, 41], labeled with FAM and HEX fluorophores. The PCR mixture of 50 μL included DreamTaq DNA Polymerases (Thermo Fisher, USA), primers, DNA template, and deionized water. Amplification occurred in a SimpliAmp Thermal Cycler (Thermo Fisher, USA) with specific cycling parameters: initial 3 min at 93°C, followed by 30 cycles of 30 s each at 93°C, 60 °C, and 72°C, concluding with a 10 min cycle at 72°C. After amplification, the amplicon was purified using QIAquick PCR Purification and digested with endonuclease BsuRI (Thermo Fisher, USA) at 37°C for 3 hours. T-RF scanning was performed by SolGent (South Korea) with data processed using the Peak Scanner (Thermo Fisher, USA). T-RFs were sorted, and their relative abundance was determined using the “readr”, “dplyr”, and “tidyverse” packages in R.
2.7. Indicator Species Analysis
The T-RF data obtained through T-RFLP analysis was utilized for the assessment of indicator species specific to certain acid pollutants. The T-RFs and their relative abundance from each soil sample were organized into a data frame format. After standardizing this data frame, it was analyzed using the ‘Indicspecies’ package in R. Based on the analysis, data on indicator species for each acid pollutant and other species were separately extracted.
2.8. Data Augmentation
Data augmentation was carried out using Python. The numpy and pandas libraries were employed for data processing, and Keras was utilized to establish a generative adversarial network (GAN) model. The data frame was organized such that the first column represented samples, the second column denoted acidic pollutants, and the columns from the third onward contained data. Additionally, standardization was performed on this data. For the model, the generator was designed with an initial input of 100 nodes, followed by layers with 256, 512, and 1024 nodes, respectively. The final layer contained nodes equivalent to the number of features in the original data, employing a ‘linear’ activation function. The discriminator was constructed with layers housing 1024, 512, and 256 nodes sequentially, with its final layer utilizing a ‘sigmoid’ activation function. During model training, the Adam optimization algorithm was used. The learning rate, set at 0.0002, controlled how swiftly the model learned, ensuring stable training. Additionally, a beta1 value of 0.5 was set, determining the extent to which past gradient information was reflected. The configured model underwent training for a total of 1000 iterations (epochs). Using the trained generator, 20 new sample data points were generated for each acidic pollutant.
2.9. Machine Learning for Pollutant Prediction
Various machine learning algorithms were experimented with to predict acidic pollutants. The raw data was loaded using the pandas package and preprocessed with numpy. After removing missing and outlier values, the data was standardized and split into training and testing sets at an 80:20 ratio. The support vector machine (SVM) was trained using sklearn with a linear kernel and C=1. For the K-nearest neighbors (KNN), the number of neighbors was set to 3. The random forest (RF) was configured with 100 trees, and the artificial neural network (ANN) was designed using tensor-flow with two dense layers (128 and 64 neurons) and a softmax output layer. The performance of each model was evaluated using accuracy, classification reports, and confusion matrices. For visualization, 2D PCA, neural network diagrams, and confusion matrices were used.
3. Results & Discussion
3.1. Changes in Soil pH Due to Acidic Contaminants
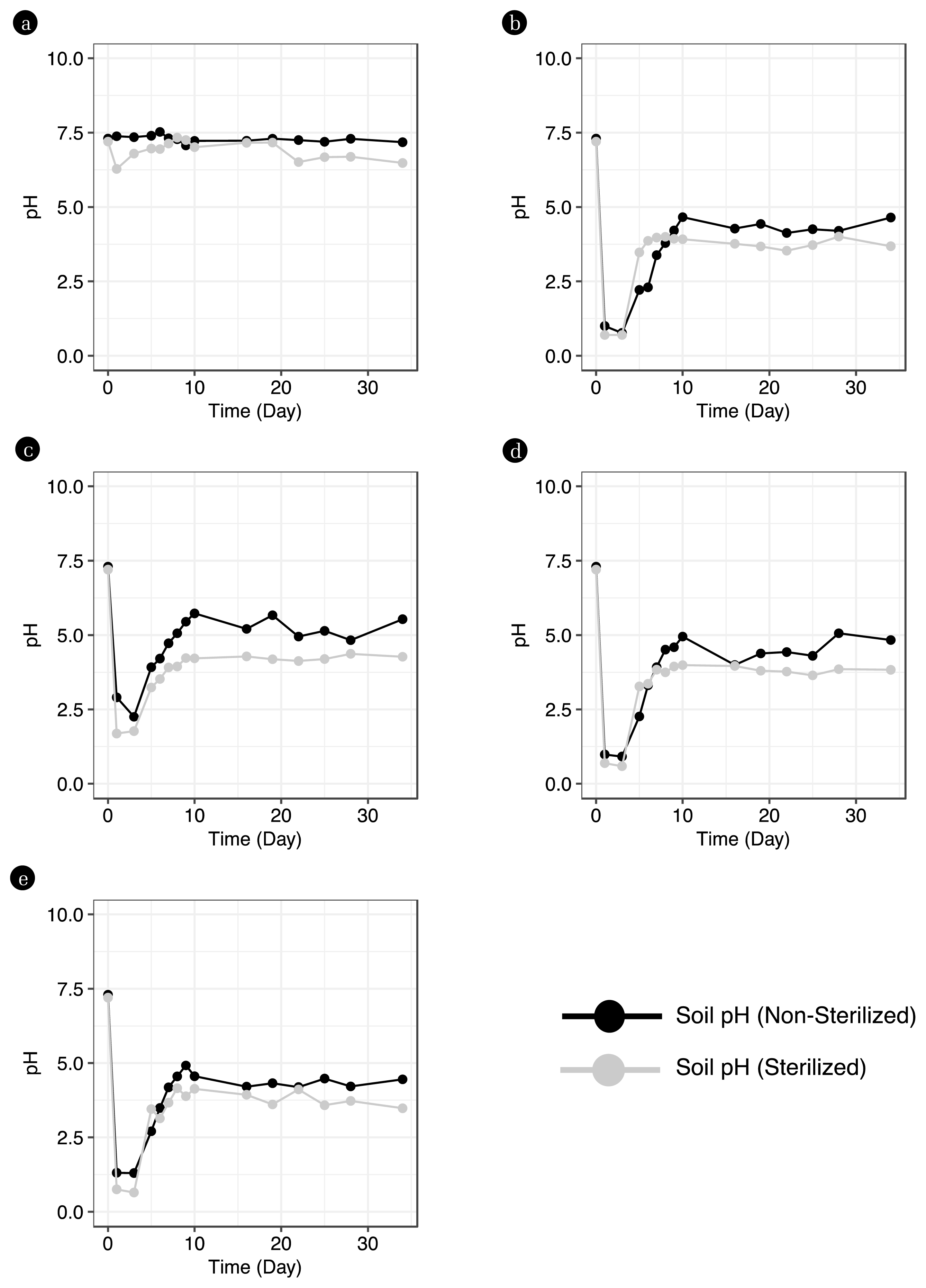
To monitor the soil pH over time following the acidic substance leak, tap water (W-column), HCl (C-column), HF (F-column), HNO3 (N-column), and H2SO4 (S-column) were leaked into both the five non-sterilized soil-filled columns and the five sterilized soil-filled columns on days 1 and 3. Subsequently, using tap water, periodic rainfall was simulated for 34 days, and the top layer of soil from the columns was periodically collected to measure the pH.
As a result, after the acidic contaminant leak, a rapid decrease in pH was observed in both the five sterilized and the five non-sterilized soil samples. In both conditions, the soil showed an increasing pH trend for about 10 days, after which the pH in the soils with the leaked acidic contaminants stabilized at around 4.5±0.5 and 3.9±0.2, respectively, for the remainder of the period. Notably, the non-sterilized soil displayed a gradual rise in pH, while the sterilized soil experienced a more abrupt increase (Fig. 1). For both soil conditions, a rapid pH decline to below 3 was observed in the C, F, N, and S-columns contaminated by acidic pollutants on days 0 and 3. Specifically, on day 3, the non-sterilized soil in the C-column showed a minimum pH of 0.76, while the sterilized soil in the N-column exhibited a pH as low as 0.58. Then, both soil conditions displayed a trend of soil pH recovery by day 10. After 10 days, the non-sterilized soil showed average pH values of 4.37, 5.29, 4.56, and 4.34 in the C, F, N, and S-columns, respectively, until the end of the experiment. For the sterilized soil, the C, F, N, and S-columns recorded average pH values of 3.75, 4.23, 3.83, and 3.79, respectively. Both soil conditions exhibited distinct trends in pH recovery after exposure to acidic contaminants. Upon leakage of acidic pollutants, both soil types showed a pH drop to values below 3. These findings suggest that regardless of the presence or absence of soil bacteria, exposure to these contaminants can produce detrimental effects on the soil. The introduction of acidic pollutants leads to a reaction with the soil’s moisture, producing anions and hydrogen ions. This surge in hydrogen ions results in a pH drop and serves as a primary toxicant to bacteria, culminating in a decrease in microbial diversity and negatively impacting the soil [5, 9, 10].
However, during the simulated rainfall period, the trend of pH increase in the soil differed between the two conditions. This suggests that the pH of soil contaminated by acidic pollutants might vary according to the soil’s buffering capacity. In the context of soil, the presence of soil bacteria contributes to nutrient cycling and plays a role in buffering [42]. From days 3 to 10, as the soil’s pH started to recover, the large amount of hydrogen ions supplied by the acidic pollutants bound with the organic matter in the soil, forming organic compounds. These compounds, when utilized by acidophilic bacteria, facilitate the cycling of hydrogen ions, leading to a gradual increase in pH [43, 44]. On the other hand, in sterilized soil where the activity of soil bacteria was eliminated, the pH sharply increased, presumably due to the easier adsorption by rainfall or the leaching away of hydrogen ions [45]. This demonstrates that the presence of bacteria contributing to the soil’s buffering characteristics can be used as an indicator to assess the condition of the soil.
3.2. Bacterial Community Structure
3.2.1. Next generation sequencing
To compare the bacterial community structure in the soil at the beginning and end of the acid leak, soil samples were collected from the top layer of the five non-sterilized soils where tap water, HCl, HF, HNO3, and H2SO4 had leaked. Ten samples were collected for 16S rRNA gene amplicon sequencing.
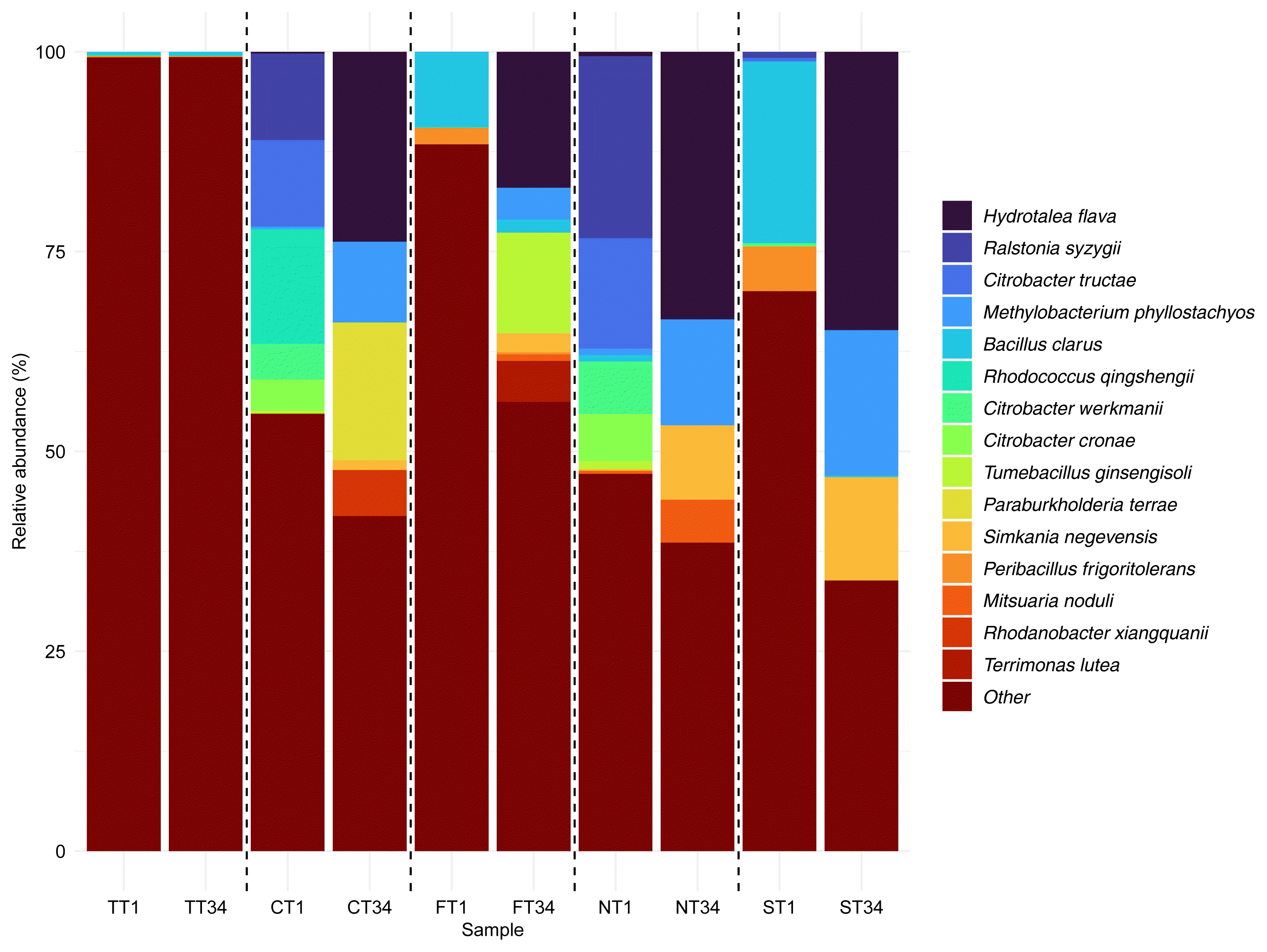
From this analysis, 327,200 high-quality bacterial sequences were obtained, which were further categorized into 6,448 ASVs. Fifteen bacterial species, showing a relative abundance of over 5% at least once in the samples, were identified as the main species (Fig. 2). The top three species in each sample were analyzed and are presented in Table 1. In the initial stages of acidic leakage, species such as Ralstonia syzygii, Citrobacter tructae, Citrobacter werkmanii, Citrobacter cronae, Bacillus clarus, and Rhodococcus qingshengii exhibited high dominance. The average relative abundance of these species in the initial acidic leakage samples was 8.6 ± 10.6%, 6.2 ± 7.0%, 2.8 ± 3.2%, 2.4 ± 2.8%, 8.2 ± 10.5%, and 3.5 ± 7.1%, respectively. After the acidic leakage, Hydrotalea flava, Methylobacterium phyllostachyos, Simkania negevensis, Paraburkholderia terrae, and Tumebacillus ginsengisoli were predominant. In the 34-day post-leakage samples, their average relative abundances were 27.2 ± 8.4%, 11.3 ± 5.9%, 6.4 ± 5.5%, 4.3 ± 8.6%, and 3.1 ± 6.2%, respectively. In the samples of CT1 and NT1 where HCl and HNO3 leaked, an increase in the relative abundance of Ralstonia syzygii, Citrobacter tructae, Citrobacter werkmanii, and Citrobacter cronae was observed. Specifically, in CT1, they showed relative abundances of 10.8%, 10.8%, 4.4%, and 3.9% respectively. In NT1, these percentages were 22.7%, 13.8%, 6.5%, and 5.9% respectively. Notably, in CT1, following the HCl leakage, Rhodococcus qingshengii also held a significant proportion, with 14.2% relative abundance. In FT1 and ST1, where HF and H2SO4 leaked, Bacillus clarus exhibited substantial presence, with relative abundances of 9.4% and 22.7%, respectively.
Following the simulated rainfall, after 34 days, all soil columns showed a high relative abundance of Hydrotalea flava, Methylobacterium phyllostachyos, and Simkania negevensis. Specifically, in CT34, FT34, NT34, and ST34, the relative abundances for Hydrotalea flava were 23.7%, 17.0%, 33.4%, and 34.8%, respectively. Methylobacterium phyllostachyos held considerable proportions, with relative abundances of 10.0%, 3.9%, 13.2%, and 18.1% in these columns. In CT34, where HCl had leaked, Paraburkholderia terrae exhibited a relative abundance of 17.2%. In FT34, affected by the HF leakage, Tumebacillus ginsengisoli held a relative abundance of 12.5%.
In the initial phase of acid leakage, Ralstonia syzygii, known to reduce nitrate to nitrite, displayed a high relative abundance [46], suggesting its prevalence in nitrate-affected soils. Species from the Citrobacter genus also exhibited an elevated relative abundance during this phase. Citrobacter spp. is documented to thrive even in low pH conditions [47]. Specifically, Citrobacter tructae and Citrobacter werkmanii are reported to produce indole related to plant hormones [47, 48]. Citrobacter werkmanii has been recognized for forming robust and stable biofilms. Genetic investigations have identified the presence of genes associated with quorum sensing, such as bsmA, bssR, and bssS, along with a multitude of biofilm-associated genes, including hmsP, tabA, and the csg gene cluster [49, 50]. The formation of such biofilms likely offers protection against physical, chemical, and biological stresses, facilitating attachment to soil surfaces and preventing bacterial washout in dynamic environments, thereby maintaining a high population density. Citrobacter cronae, reported as a close relative to Citrobacter werkmanii, was first identified near the human rectum, indicating its potential to thrive in slightly acidic conditions (pH 5~7) [51]. Rhodococcus qingshengii has been associated with influencing nitrogen cycling in soil environments and is known to assist in the remediation of soils affected by carbendazim [52, 53], which has a reported acidity of pH 4.48. This suggests the bacterium’s ability to persist in low pH environments, potentially accounting for its high relative abundance.
After 34 days, when the soil’s pH had shown considerable recovery, Hydrotalea flava exhibited an elevated relative abundance. This bacterium has been identified in acidic mine drainage, which possesses notably low pH levels, suggesting its adaptability to such conditions [54]. Methylobacterium phyllostachyos, known as a methylotrophic bacterium [55], indicates the production of methyl-related compounds in the soil, signaling ongoing soil remediation. Paraburkholderia terrae has been reported to symbiotically coexist in the roots of leguminous plants alongside Rhizobium and also demonstrates a symbiotic relationship with certain fungi [56, 57]. Its capabilities, such as metabolizing aromatic compounds and fixing nitrogen [58, 59], are indicators of soil health and restoration. Tumebacillus ginsengisoli, characterized by its spore formation and growth at pH 5 [60], is presumed to have accounted for its high relative abundance in soil impacted by HF leakage.
3.2.2. Terminal restriction length polymorphism
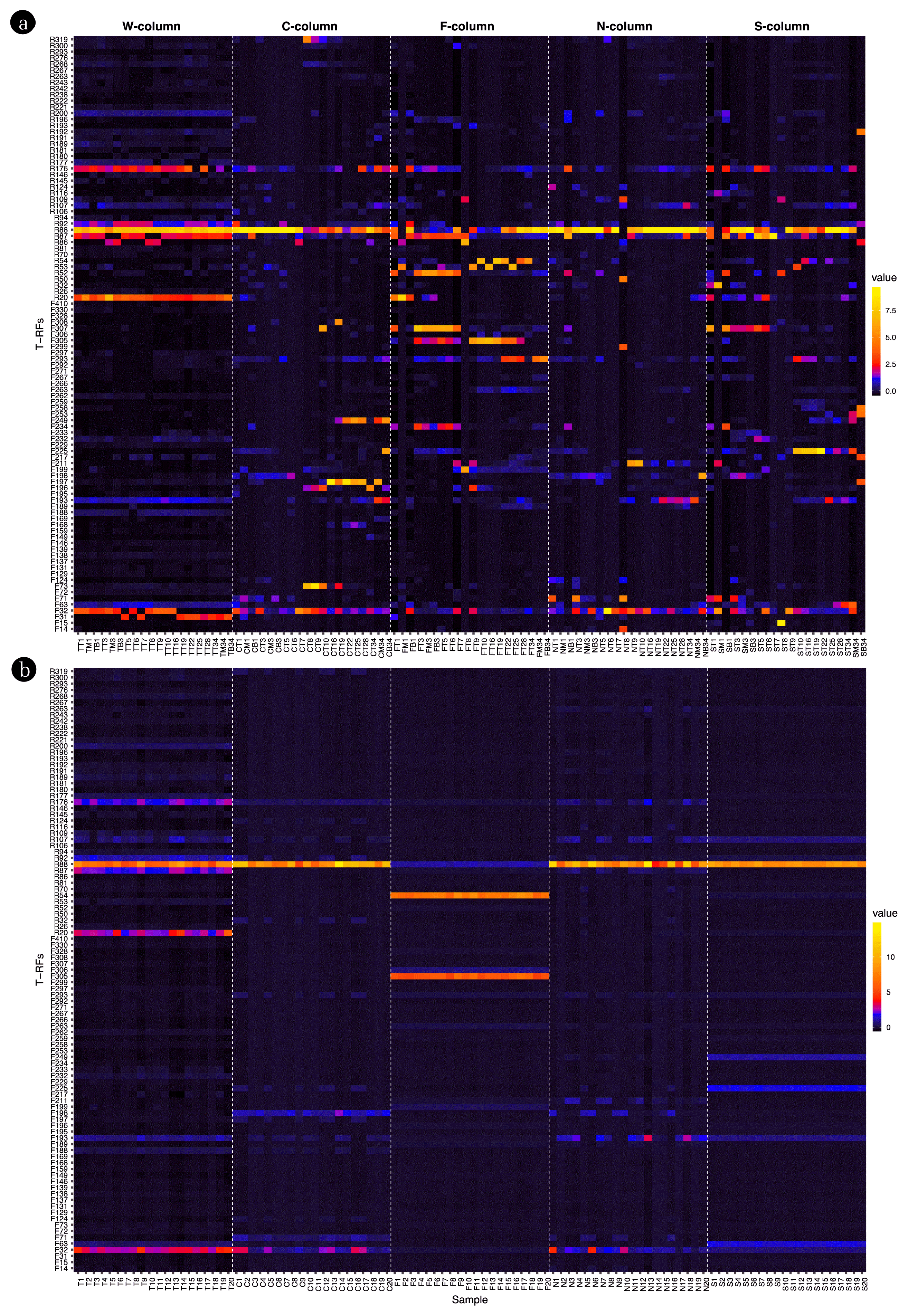
To examine the temporal changes in the soil bacterial communities affected by acidic contaminants in the soil, T-RFLP analysis was performed on the 100 collected samples using the 27F and 518R primers and the BsuRI restriction enzyme.
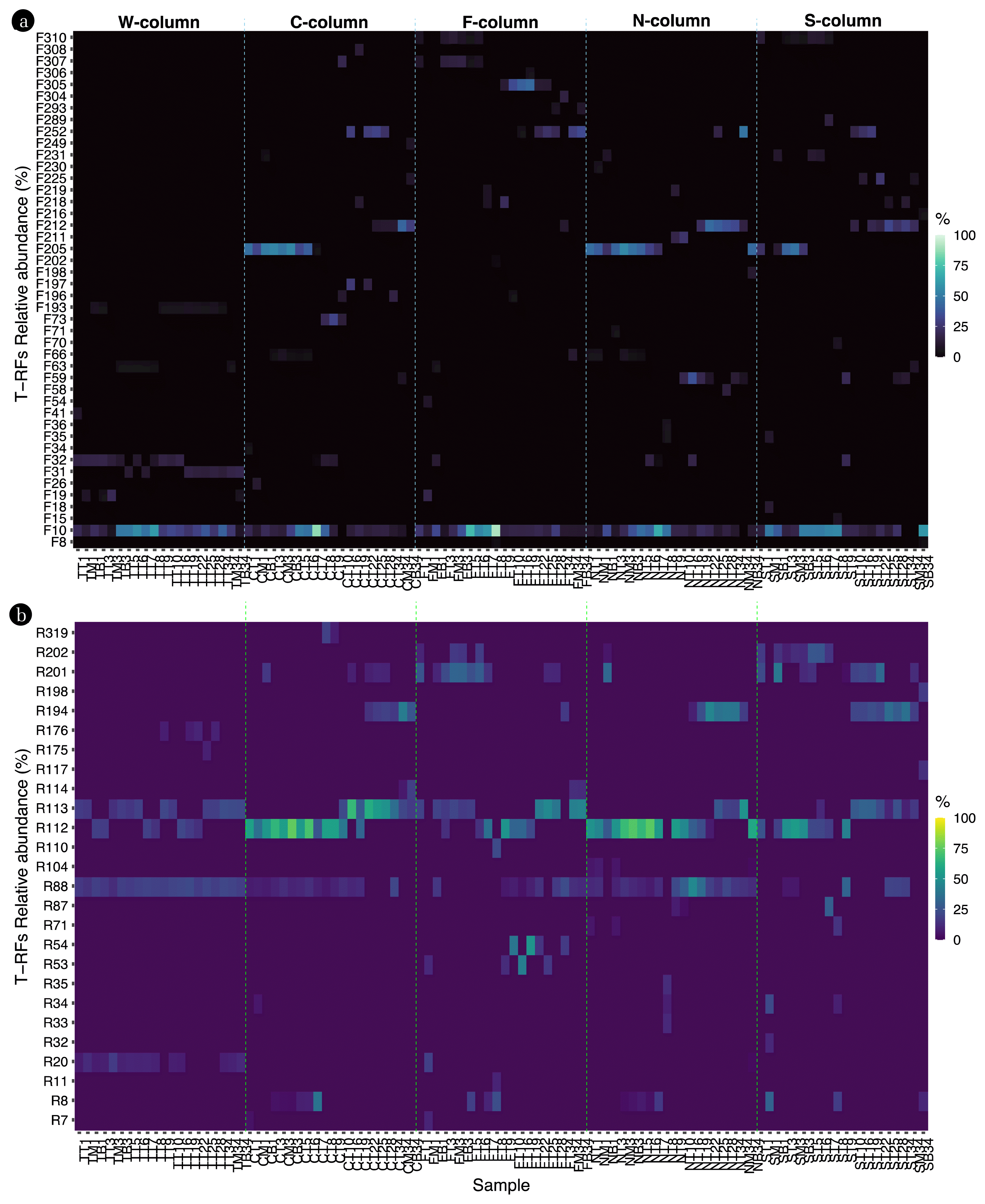
From the analysis, 338 T-RFs were identified using the 27F primer, and 291 T-RFs were identified using the 518R primer, resulting in a total of 629 T-RFs being identified. Notably, using the 27F primer led to the detection of 44 key T-RFs (Fig. 3a) while 27 T-RFs were detected with the 518R primer (Fig. 3b). During the early stages of acid leaking, F205 and R112 showed a high relative abundance. Upon pH recovery of the soil, F212, F252, R113, and R194 exhibited a high relative abundance as well. Intriguingly, some T-RFs were exclusively detected in soils affected by specific acidic contaminants. For instance, T-RFs such as F26, F34, F73, F197, F249, F308, and R319 were observed only in HCl-affected soils. In HF-affected soils, the T-RFs included F54, F202, F293, F304, F305, F306, R11, R53, R54, and R110. For HNO3 affected soils, the T-RFs were F36, F58, F71, F198, F211, F230, R33, R35, and R104, and for H2SO4 affected soils, they were F15, F18, F70, F216, F289, R32, R117, and R198.
During the initial stages of acid leaking, F205 and R112 demonstrated a high relative abundance, and after the acid leakage, F212, F252, R113, and R194 showed a notable relative presence. F205 and R112 could be proposed as early indicators for assessing soil conditions immediately after acid leakage, while F212, F252, R113, and R194 have potential as markers for evaluating soil conditions after pH recovery. Additionally, the unique T-RF patterns, resulting from specific acidic contaminants, suggest the possibility of identifying the respective contaminants.
3.3. Indicator T-RFs for Forensics
To select statistically significant T-RFs associated with acidic contaminants from the 629 T-RFs identified through T-RFLP experiments, indicator species analysis was conducted using the ‘Indicspecies’ package in R.
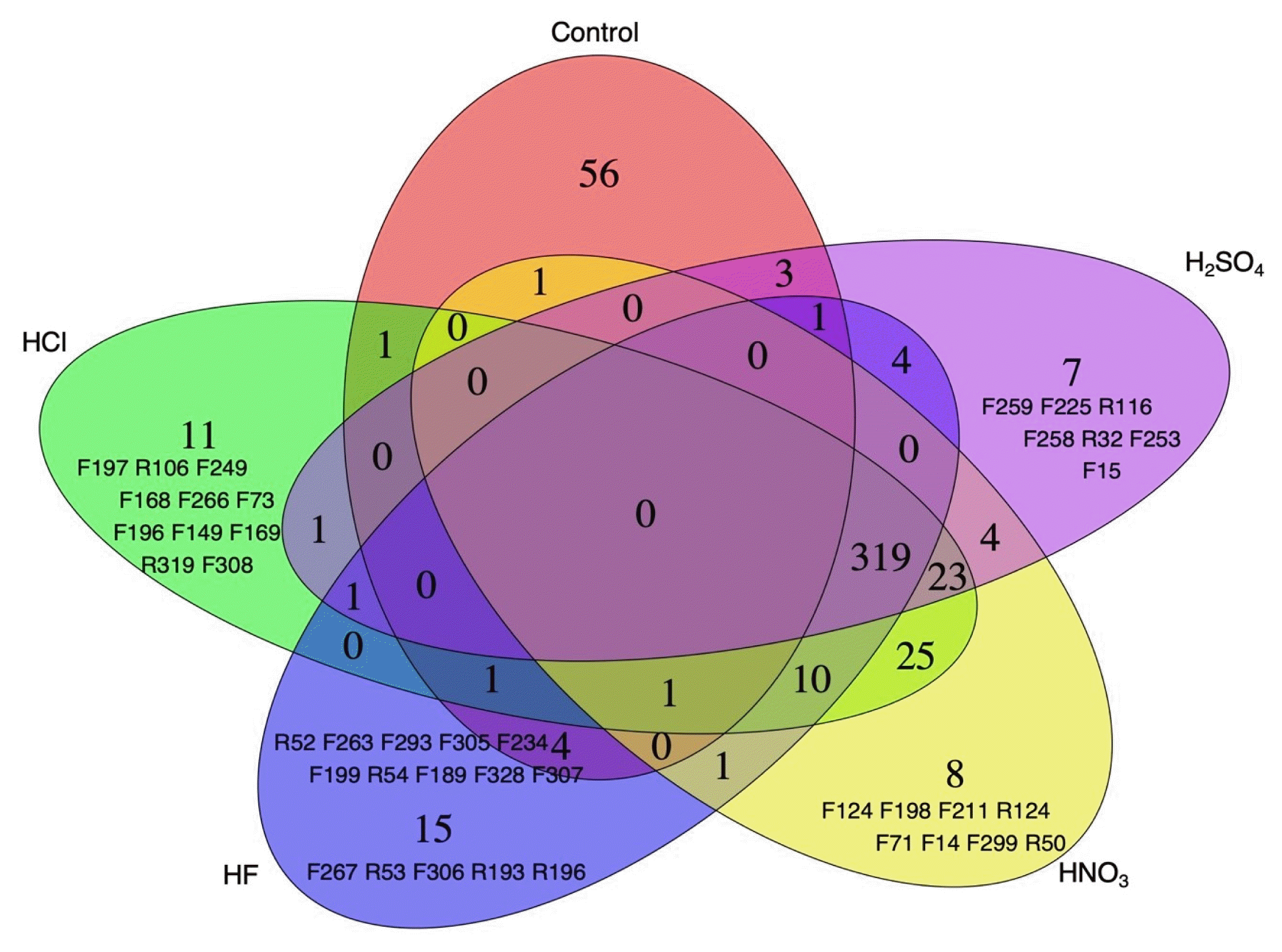
Among the 629 T-RFs analyzed, 497 were identified as indicators for acidic pollutants. Specifically, 97 T-RFs were associated with any one of the five acidic pollutants, 44 T-RFs were associated with a combination of two out of the five acidic pollutants, 36 with a combination of three acidic pollutants, and notably, 320 T-RFs were associated with four distinct acidic pollutants (Fig. 4). In soils contaminated with HCl, 11 marker species were identified with F197, R106, F249, and F149 being the most significant. For soil samples exposed to HF, out of the 15 detected species, R52, F263, F293, F305, F234, F199, R54, and F189 were the primary indicators. In the HNO3 contaminated soils, F198 was notably significant among the 8 species. Lastly, in the soils exposed to H2SO4, F259 and F225 were the principal markers out of the 7 identified species. These findings highlight the statistical significant associations of the respective T-RFs.
Despite not having a high relative abundance, specific T-RFs such as R106, F149, R52, F263, F199, F189, F198, F259, and F225 were identified as indicator species. The selection of these T-RFs as indicator species is likely attributed to their heightened sensitivity and representativeness to environmental changes. Some bacteria are recognized as indicator species due to their unique biological traits, like reproductive or metabolic capabilities [61, 62]. Bacteria with high relative abundance might exhibit rapid growth rates because they can metabolize a variety of compounds, including specific substances. In contrast, bacteria with lower relative abundance might grow slower since they only metabolize specific compounds. According to one report, slow-growing bacteria utilize fewer resources, while fast-growing ones thrive due to their ability to use a multitude of resources. Moreover, the bacterial type, such as Gammaproteobacteria, has been reported to influence the rate at which bacteria grow [63].
Based on these findings, it was hypothesized that indicator species with lower relative abundance might reflect more robust representativeness towards specific contaminants than those with higher relative abundance. Particularly, the sensitivity of such indicator species is likely based on the expression of specific genes [64, 65]. Expressions of genes related to enzyme activities are known to occur more rapidly than changes in soil bacterial diversity indicators. Therefore, the development of T-RFLP analysis targeting functional genes responding to acidic stress is required for more accurately identifying indicator species. In soil environments near mines with low pH values, genes related to dehydrogenase, fluorescein activity, and peroxidase serve as bioindicators [66]. In soils contaminated with organic pollutants, the expression of stress proteins like hsp70 and hsp60 is used for biological monitoring against metal and organic soil exposure [64, 67]. By analyzing these sensitive indicator species targeting specific functional genes, more relevant indicator species can be precisely identified.
3.4. Data Augmentation and Machine Learning-based Forensics
To predict acidic contaminants, four machine learning algorithms – SVM, KNN, RF, and ANN – were used. The input data consisted of 100 samples containing information on 97 T-RFs that are indicator species for a specific contaminant, and an additional 100 samples were doubled using GAN for data augmentation (Fig. 5).
As a result, using the original 100 samples without augmentation, SVM and KNN showed an accuracy of 72%, but ANN demonstrated the highest performance with 88% accuracy (Table 2). On the other hand, when using a total of 200 samples, including both the original 100 samples and the additional 100 augmented samples, all machine learning algorithms improved their accuracy in predicting acidic contaminants. Notably, ANN achieved a high accuracy of up to 98%. When using the non-augmented samples, the recall values, which indicate how well the models correctly identified the actual cases, for H2SO4 in SVM, KNN, RF, and ANN were relatively low at 40, 20, 40, and 80%, respectively. However, a notable improvement was observed when using the augmented samples as input data; the recall for H2SO4 increased to 90, 70, 70, and 90%, respectively. These results suggest that using GAN can amplify the characteristics of specific samples [36, 68].
The advancement of molecular biology equipment has significantly reduced the time and cost of conducting molecular biology experiments [17]. However, obtaining biological da ta still requires intensive time and costs due to complex procedures, including molecular biological monitoring such as T-RFLP, which can take up to a day to process and yield results [69, 70]. Moreover, the rigorous screening process in selecting crucial data, such as indicator species, often reduces the amount of available information. It has also been reported that a small amount of input data is insufficient for building a proper ANN model, leading to research estimating the minimum sample size needed to address this issue [71, 72]. In supervised machine learning algorithms, a small amount of input data often leads to overfitting during the training phase, preventing the model from being perfectly generalized [73, 74]. Therefore, there are many efforts to avoid this through cross-validation, regularization, dimensionality reduction, and data augmentation [75, 76]. Especially, data augmentation can prevent overfitting by increasing the diversity of data, thus allowing the model to be trained to respond to a variety of scenarios [76, 77]. A forensic study processed 50 samples using two restriction enzymes, HhaI and AluI, to generate T-RF data for increased accuracy [78]. Another study in nitrogen treatment bioreactors used the SMOTE (Synthetic Minority Over-Sampling) technique to generate additional data points, resulting in an increase in prediction accuracy from 84% to 88.2% [38]. Therefore, if molecular biological data generated from a limited number of experiments can be meaningfully augmented, it could be a cost-effective method for environmental monitoring.
When comparing machine learning algorithms, both SVM and KNN showed an identical accuracy of 72% in predicting acidic contaminants, which is believed to be due to their methods of learning the relationship between input values and target variables. As the volume of data increases, SVM determines a decision boundary using a hyperplane to separate multiple classes, classifying all data within this boundary into one category (Figs. S1 and S5) [79, 80]. In contrast, the performance of KNN depends on the number of nearest neighbors, K, considered, and increasing K can also increase the computational time (Figs. S2 and S6) [81, 82]. This distinction between the two algorithms suggests that as the quantity of data grows, there will be a difference in performance. In conclusion, setting a decision boundary to classify data within a particular region is anticipated to be more effective for processing large datasets than connecting multiple lines [83]. RF may not always be effective in handling large datasets. Composed of multiple decision trees, RF can produce consistent results regardless of the data volume if there are distinct features in even a small amount of data, allowing for classification based on several questions (Figs. S3 and S7) [84–86]. This suggests that RF can achieve excellent performance with limited data. However, data quality is crucial, and the risk of overfitting should not be overlooked [87, 88]. ANN is based on the principles of biological neural networks, leveraging multiple neural network layers to capture the intricate features and relationships within data (Figs. S4 and S8). Such a structure underscores the superior performance of ANN when juxtaposed with other machine learning algorithms (Table 2). Notably, during the learning process of ANN, back-propagation is utilized to compute the derivative of the loss function, adjusting the weights of each node to minimize errors. Increased computations and iterative error corrections adeptly reflect the complexity and diversity of the data [89, 90]. Hence, when employed with a substantial dataset, ANN has demonstrated an impressive accuracy of up to 98% [72, 91]. When comparing the four machine learning algorithms, it is evident that ANN stands out due to its unique advantages in predicting acidic contaminants. Inspired by the structure of biological neural networks, ANN leverages multiple layers to intricately capture features and relationships within data. This complex structure, combined with its ability to adjust weights through backpropagation and handle the complexity and diversity of large datasets, makes ANN particularly effective for such predictions, as evidenced by its impressive accuracy of up to 98%.
4. Conclusions
The experiment on acid leakage revealed a rapid decrease in soil pH, and while it recovered over time, sterilized and non-sterilized soils showed different recovery patterns. From the 16S rRNA amplicon sequencing, Ralstonia syzygii and Citrobacter spp. dominated initially, but later, Hydrotalea flava and Methylobacterium phyllostachyos emerged as the primary bacteria. The T-RFLP study unveiled temporal changes in the bacterial community due to acid leakage and suggested the potential of identifying pollutants through unique T-RFs patterns. The dataset was augmented using the indicator species data, bringing the total to 200 samples. Testing with machine learning algorithms, ANN demonstrated the highest accuracy, achieving 88% and 98% with the original and augmented datasets, respectively. These results provide a deeper understanding of the differences among machine learning algorithms and performance variations depending on dataset size.