1. Introduction
With the continuous development of social modernization and industrialization, the ecological environment has been constantly damaged, environmental protection has increasingly become the focus of social attention, especially the worsening air pollution [1]. Aerosol particles, especially aerosol particles less than 2.5 microns in diameter (PM2.5), have a negative impact on human health and can lead to asthma, lung cancer, cardiovascular disease and other diseases [2, 3]. Therefore, high-precision PM2.5 prediction has positive significance for human health management and government environmental management decision-making. PM2.5 concentration prediction is a typical time series prediction problem by using the relevant time series information of history and current time to predict the future PM2.5 concentration [4, 5]. However, due to the formation of PM2.5 and the influence factors of PM2.5 concentration, there is still no unified understanding. At the same time, all kinds of influence factors have certain randomness, which increases the difficulty of PM2.5 concentration prediction.
At present, prediction methods can be divided into traditional time series modeling, machine learning and deep learning. The spatiotemporal correlation multi-step prediction of PM2.5 concentration is the research of estimating the PM2.5 concentration in the future by using the law of time and space obtained from the summary or mining of historical data. It belongs to the category of spatiotemporal prediction, and its research content can be divided into two parts: spatial distribution feature extraction and sequence prediction of PM2.5 concentration [6]. As a typical linear modeling method in traditional time series modeling, Auto regressive Integrated Moving Average model (ARIMA) can get time series characteristics, but it cannot get the complex nonlinear relationship in PM2.5 data, so it can’t get good prediction effect [7]. The shallow network based on machine learning can model the complex nonlinear relationship in time series data, but because the network structure is relatively simple, it can only obtain the changes of short-term time series, and is only suitable for short-term prediction [8]. To get accurate long-term forecasts, more complex networks that capture long-term changes must be used. Deep learning has shown significant advantages in dealing with complex time series, so it has attracted more attention in PM2.5 concentration prediction [9].
Based on the above analysis, aiming at the problems of short prediction time and poor generalization ability of some PM2.5 concentration prediction models, a PM2.5 concentration prediction model based on deep learning under the Internet of Things (IoT) air detection system is proposed. The innovation of the proposed model is summarized as follows:
Due to the discontinuity of data sequence in time dimension, the problem of data missing often occurs in the real scene. The proposed model uses cubic spline function interpolation method, which can smooth the transition fitting curve at the junction of each sub interval, and obtain an ideal data set.
In order to improve the prediction accuracy, the proposed model adopts an encoder decoder network structure, and uses a threshold cyclic unit network which is more suitable for processing long time series to encode and decode features. The temporal attention mechanism is integrated into the model to improve the generalization ability of the model.
2. Related Work
At present, the prediction methods mainly include deterministic model and statistical model. Deterministic model is a theoretical simulation method, which fully describes the complex physical and chemical changes in the diffusion and dilution process of air pollutants [10]. Among them, statistical model is a method to analyze a large number of air quality data and meteorological data by using various numerical simulation techniques to mine potential laws [11]. In addition, there are a large number of PM2.5 concentration prediction models based on machine learning, such as support vector machine, random forest, Seq2seq model.
The traditional statistical model method is to use vector autoregressive model, ARIMA and other models [12]. In Cheng et al. [13], a 3D variational lidar data assimilation method was developed in combination with weather forecast model, and an assimilation system for lidar observation data was established for PM2.5 concentration prediction, but the depth information of complex data information has not been mined yet. According to the single time series of PM2.5 data in Zhang et al. [14], a prediction model with dynamic adjustment is proposed. The model uses the number of residual states in the dynamic Markov chain to train and determine the threshold parameters, so as to achieve efficient and accurate PM2.5 concentration prediction. Nagesha et al. [15] has developed a prediction model for the concentration of particulate matter in mining area, which is used to predict the concentration of inhalable dust particles in the air near or far from the dust source. The prediction results of existing methods have good correlation and accuracy, but the prediction efficiency needs to be improved. Goldberg et al. [16] proposed a PM2.5 concentration prediction method based on high spatial-temporal resolution estimation, which can realize daily estimation through gap filling even when satellite data are lost. But it can only extract relatively simple linear features, and it is difficult to effectively extract more complex nonlinear features [17].
With the deepening of machine learning research, deep learning model is gradually favored by researchers for its powerful nonlinear feature extraction and analysis ability. Among them, with its special structure, recurrent neural network shows better performance than other models in time series prediction task [18]. Ayturan et al. [19] used deep learning method to model the short-term prediction of PM2.5 pollution in different time series. The prediction performance of three different deep learning algorithms and their combinations is evaluated, which provides a reference for the deep learning algorithm in air prediction. However, the application scope of the model is still limited and does not have good universality. Lai et al. [20] proposed a PM2.5 combination prediction model based on feature selection and support vector machine, and achieved good prediction accuracy. However, the prediction effect is poor when the characteristics of time series are not obvious. The Bayesian deep learning model proposed in Han et al. [21] uses proxy data including aerosol optical depth and meteorology as well as socio-economic data to predict air quality, and achieves good prediction results. However, the feature extraction ability of the model for time series data needs to be improved. In Yang et al. [22], a long-term short-term memory convolution neural network based on dynamic wind field distance is proposed to predict PM concentration at a specific location in the next 24 hours. But in the process of long sequence training, it is easy to appear the problem of gradient disappearance and gradient explosion. Therefore, a PM2.5 concentration prediction model based on deep learning is proposed in the air detection system of Internet of things.
3. Data Analysis and Preprocessing
3.1. Data Analysis
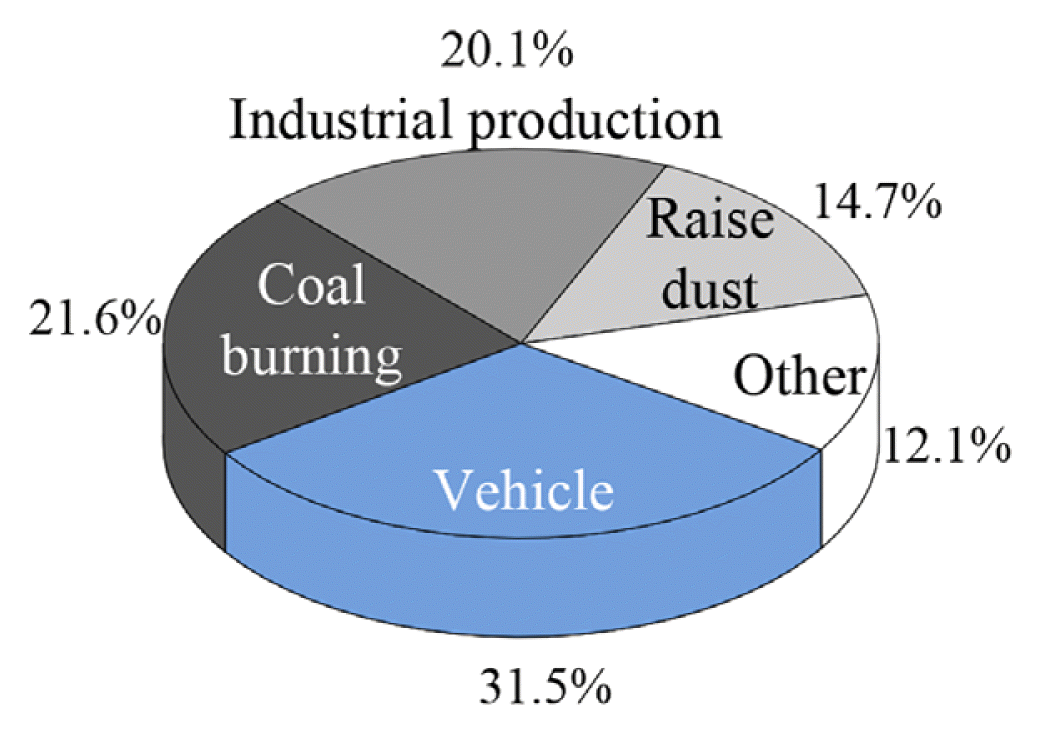
Take Beijing, one of the most serious air pollution areas in China, as an example. According to the relevant statistical data in recent three years [23], the source analysis of PM2.5 in Beijing is shown in Fig. 1. It can be seen that the largest source of PM2.5 pollution in Beijing comes from motor vehicles (31.5%), and the second largest source of pollution is coal combustion (21.6%). In addition, there are many other factors that cause PM2.5 pollution, such as industrial production and dust. These will affect the concentration of urban PM2.5 particulate matter.
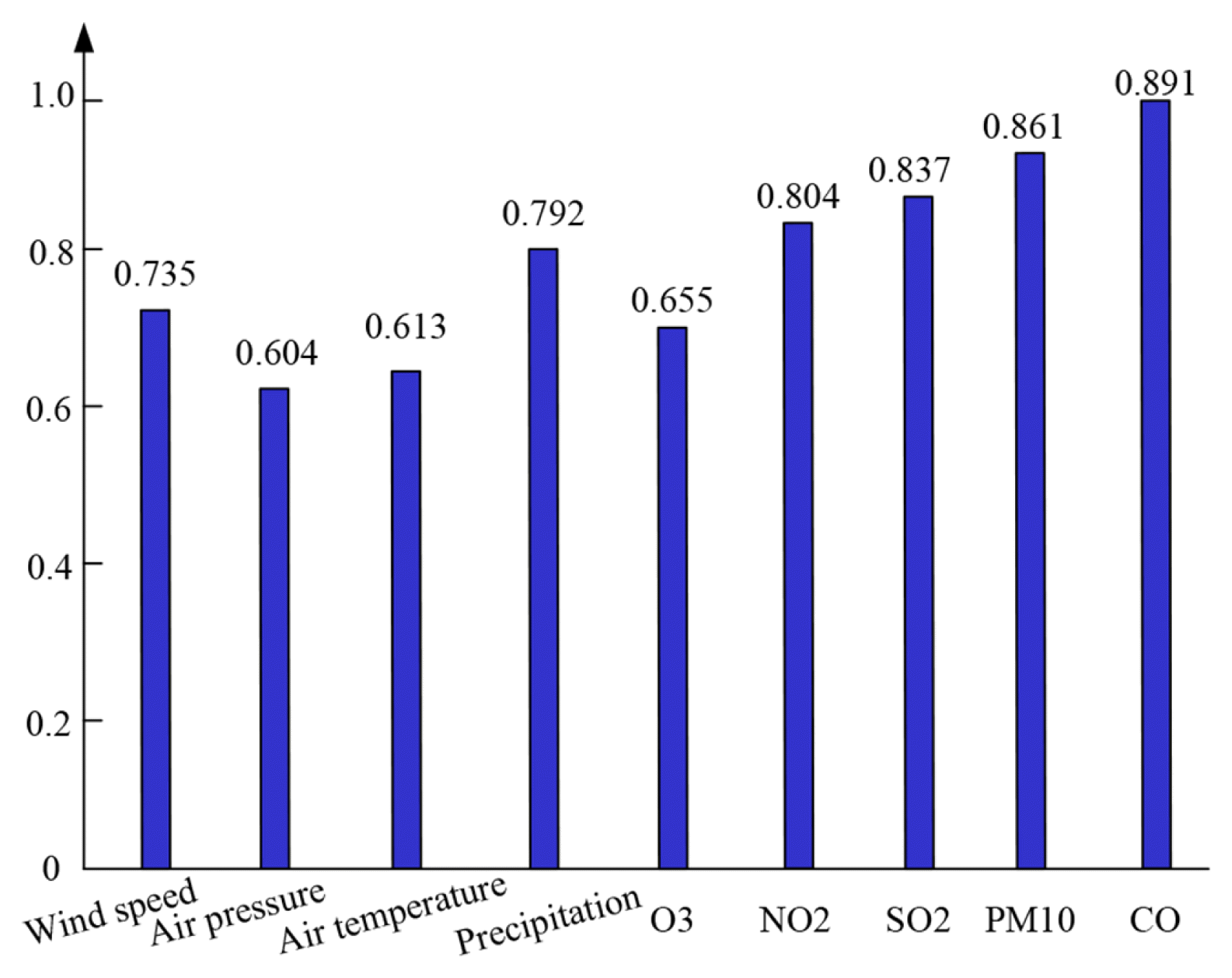
PM2.5 is the primary pollutant in the air. In the analysis of factors affecting PM2.5 concentration, in addition to the influence of atmospheric pollutants, there is also a high degree of correlation between PM2.5 concentration and meteorological data. For example, an environment with high wind speed and high air pressure will generally reduce PM2.5 concentration and improve local air quality. In order to further clarify the relationship between PM2.5 concentration and related variables, Fig. 2 shows the correlation analysis between PM2.5 concentration and various pollutant factors and meteorological factors. In addition, since the atmospheric environment is a dynamically changing system, the PM2.5 pollutants in other surrounding areas will affect the PM2.5 concentration of the target site to a certain extent through the spatial transmission effect. Therefore, it is necessary to model and analyze the spatial correlation to further improve the prediction accuracy. The 8 sites with the nearest geographic location around the target site are selected as neighboring sites, instead of using the PM2.5 concentration data of all sites in the city to extract the correlation in the spatial dimension. Its purpose is to avoid the occurrence of over-fitting problems caused by too many model parameters, and at the same time reduce the computational complexity of the model.
In summary, the feature set used is divided into three parts: (a) The concentration of various air pollutants, namely PM2.5, PM10, SO2, CO, O3, NO2; (b) Various meteorological factors, respectively Wind speed, temperature, air pressure, precipitation; (c) PM2.5 concentration of 8 nearby monitoring sites around the target site. Through modeling and analysis of the above-mentioned multiple data characteristics, the relationship between the components and the spatial-temporal variation are studied to extract the spatio-temporal correlation in the multivariate data. To achieve long-term prediction of PM2.5 concentration at the target site.
3.2. Data Preprocessing
The function of missing data filling is to deal with the missing data in multi-site multi-modal air quality time series data through software design. Since the proposed method classifies PM2.5 prediction as a time series regression problem, the input is required to be time continuous series data. However, in real application scenarios, the discontinuity of the data sequence in the time dimension often occurs, resulting in the lack of data [24]. The problem of missing multi-site and multi-modal air quality data obtained can be divided into two categories. The entire time series record is missing, and an attribute value in one record is missing. Among them, the 12-month historical data obtained from the Beijing Environmental Protection Bureau has the above two types of missing types. The real-time air quality data obtained through the web crawler can ensure the continuous time of the entire record, and there is only the problem of missing attribute values. Therefore, the processing of missing data by web crawlers can be regarded as a sub-problem of processing missing historical data.
The functional design of missing data filling software is mainly used to solve the above two types of missing data. The design of the software function requires SQL, datetime, pandas library, etc. [25]. The software design ideas adopted by the two types of problems are basically the same. All are by locating the missing time length of the time series, and adopting different missing data filling methods according to the time length. If the missing time is less than 3 h, use the value at the previous moment to fill in. For more than 3 h but less than 12 h, the missing data is filled in using the 3rd order spline function interpolation. For more than 12 h but less than 24 hours, the average value of the same period of two days before and after is used for filling [26]. For more than 24 h, divide the data set into two independent parts before and after.
Among them, for the missing data in the range of 3 to 12 h, Cubic Spline Interpolation is used to fill in the missing data. The formula is as follows:
Where, di represents the point to be interpolated, N represents the number of points to be interpolated. The second derivative
of is a piecewise linear function. Utilize the boundary conditions of N + 1 critical points to find all the ai values of the undetermined coefficients, that is, to realize the interpolation.
The cubic spline function s(d) needs to have a continuous second derivative in all segment intervals and connections, that is, the first derivative of s(d) is derivable. Therefore, the fitting curve of the cubic spline function smoothly transitions at the junction of each sub-interval, which can simulate the evolution process of the gradual change of the physical phenomenon to the greatest extent, and then obtain the ideal interpolation effect. So far, for the problem of missing data in the multi-site multi-modal air quality data, the software function based on cubic spline function interpolation is used to realize the missing value filling.
4. Research Method
4.1. Proposed Prediction Model
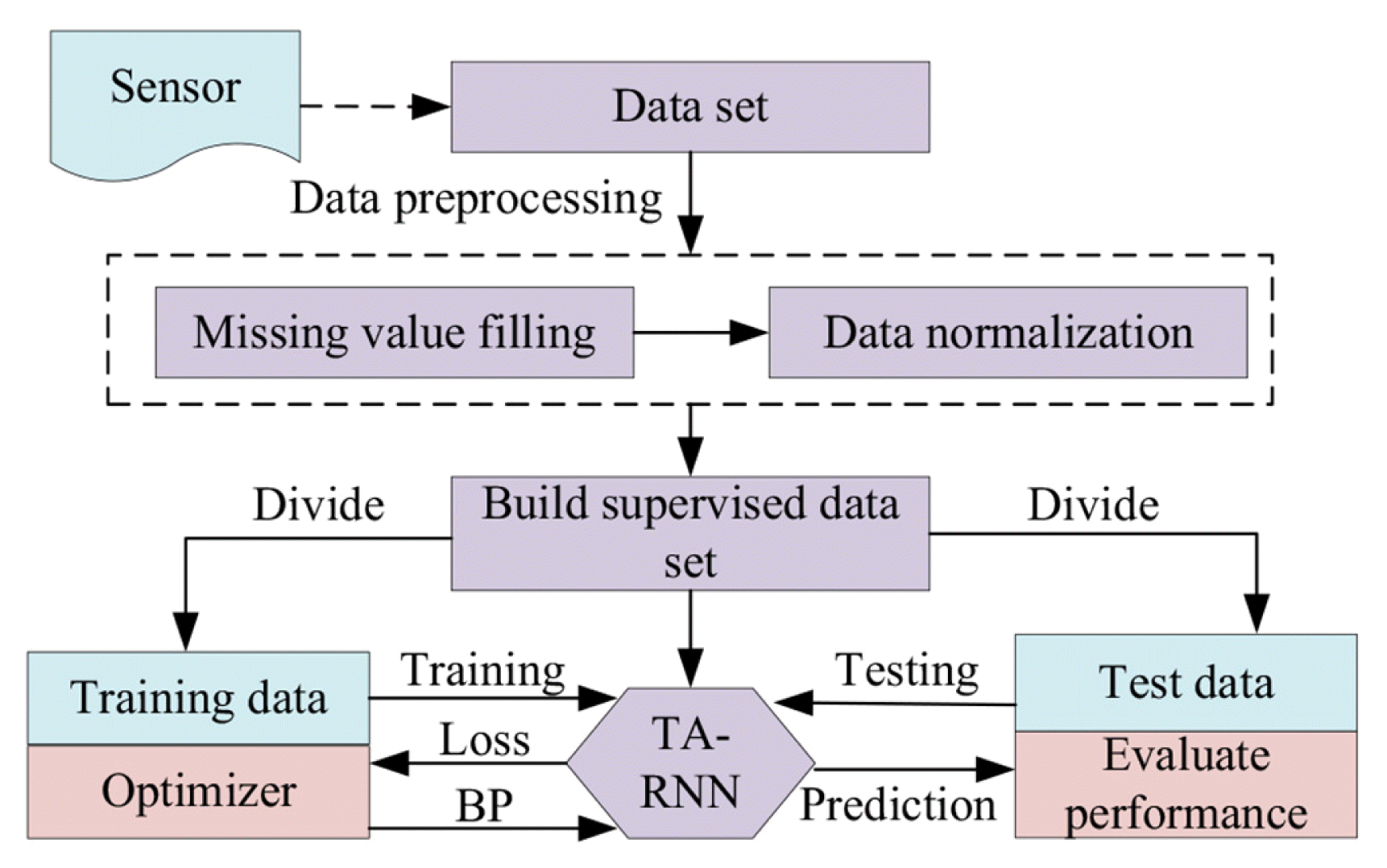
The proposed model is based on the temporal attention-recurrent neural network (TA-RNN) to achieve PM2.5 concentration prediction, and its system flow is shown in Fig. 3.
The system process can be divided into the following 5 steps:
Step 1: The sensors in the air quality and meteorological monitoring stations distributed in every corner of the city monitor and collect relevant data respectively. The collected original data set is filled with missing values and normalized. That is to say, the values of all variable dimensions are limited to the range of 0 to 1, so as not to be too biased in a certain dimension during training. The normalization method is as follows:
Where, x′ is the normalized data, x is the original input data, xmin and xmax are the minimum and maximum values in x, respectively.
Step 2: The supervised dataset is divided into training data and test data, which are used in the training and test of the model respectively.
Step 3: Within the range of the corresponding number of iterations, each batch of training sample data is selected as the input of the TA-RNN model. Forward propagation through the network will produce a corresponding loss value Loss. The optimizer adjusts the parameter values of the TA-RNN model according to this loss value through the network backpropagation.
Step 4: Input the test data into the TSMN model after training, and get the PM2.5 predicted value. Denormalize the predicted value to obtain the actual predicted value. The mathematical expression is as follows:
Where, yprime; is the predicted value of the model with a value in [0,1]. y is the actual predicted value of the model after denormalization.
Step 5: Finally, the actual predicted value and true value of the model are evaluated through a variety of evaluation indicators to analyze the performance of the TA-RNN model.
4.2. TA-RNN Model Construction
In order to improve the accuracy of the model for multivariate time series prediction, inspired by the RNN model based on two-stage attention, the TA-RNN model is designed. Its network structure is shown as in Fig. 4. First, the time sequence attention module is used to analyze the different time steps of the input multi-variable data, so as to obtain the time sequence attention of the data. Then, on the basis of obtaining the attention of each input data, update the input data and perform feature coding on it. Finally, the encoded feature matrix is fused with the historical PM2.5 concentration data, and it is input into the feature decoder for decoding to obtain the final predicted value.
TA-RNN is a multiple-input single-output model. The historical data X̃ and multivariate data X of the target sequence need to be input, and the output is the predictor variable value Y. Where, X = (x1, x2, ···, xT)T = (x1, x2, ···, xN), X̃ = (x̃1, x̃2, ···, x̃T), xt ∈ RN, xn ∈ RT, Y, yt ∊ R. N is the number of factors that affect the target sequence. T is the length of time window of model input. Therefore, the model TA-RNN can be expressed as a nonlinear function F that needs to be trained to obtain specific parameters:
PM2.5 forecasting is a typical time series regression problem. The traditional forward fully connected neural network cannot learn the influence of time series historical information on its future changing trends. RNN adds a loop structure whose output points to input on the traditional hidden layer neurons, so that RNN has the function of memorizing time series historical information. It can correlate contextual information well, especially in time series modeling.
The proposed PM2.5 prediction model uses the Dated Recurrent Unit (GRU) in RNN. It is an improved model proposed by Cho et al. based on Long-short Term Memory (LSTM). The advantage of LSTM is that the gate structure is introduced into the traditional RNN for the first time, which solves the problem of long-term dependence that RNN cannot effectively learn time series. At the same time, it alleviates the gradient dispersion (or gradient explosion) phenomenon that occurs in the RNN using the Back Propagation Through Time (BPTT) training method. This makes RNN truly play a huge role in actual application scenarios. The disadvantage of LSTM is that the output of neurons and the cell state that transmits long-term dependent information are divided into two parts, which are calculated independently, and there is a certain redundancy.
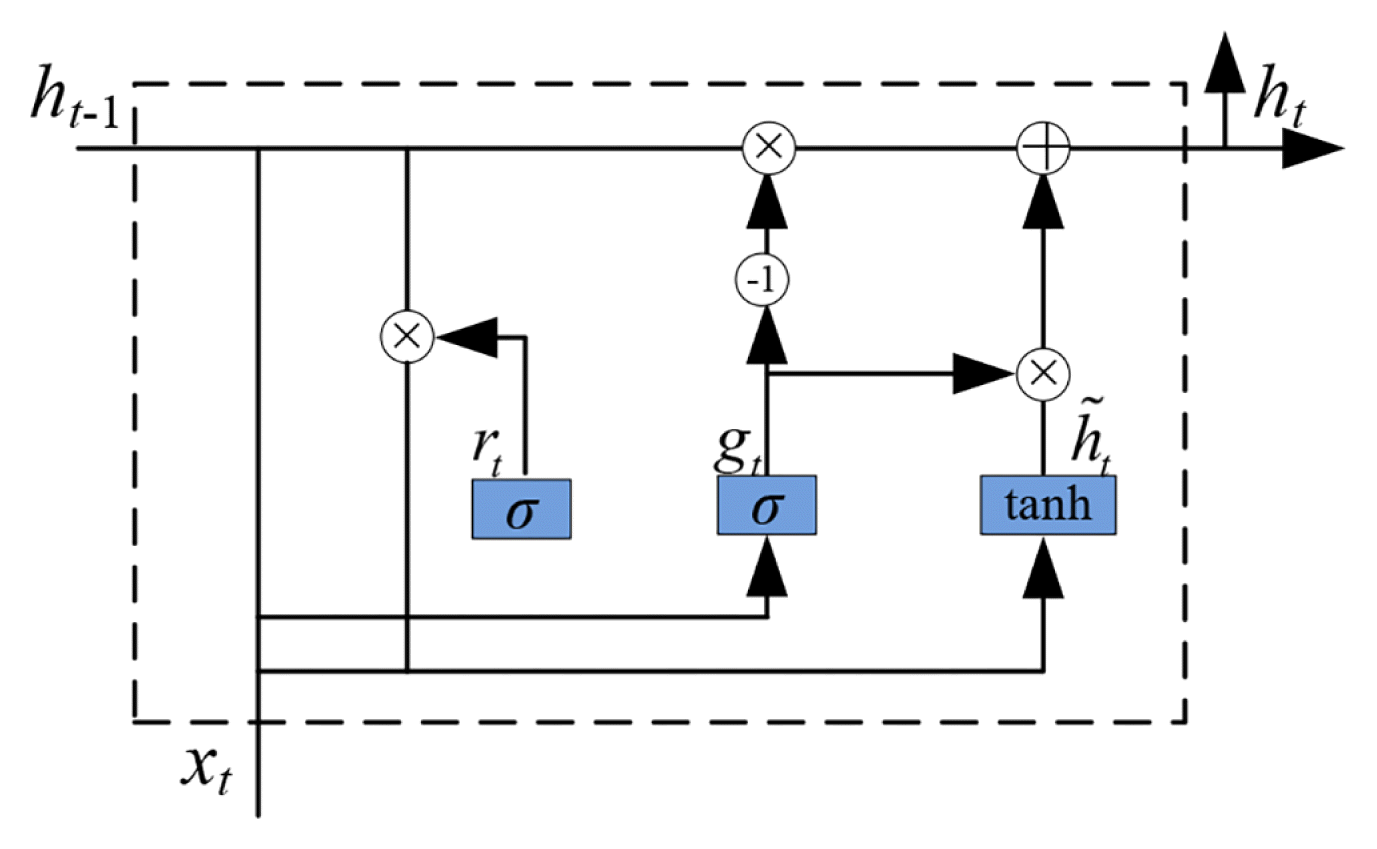
The emergence of GRU changed this status quo. It combines the input gate and forget gate in LSTM into one update gate. The reset gate corresponds to the output gate in LSTM. This reduces the original three door structure to two. The corresponding model parameters are reduced by one third. At the same time, GRU merges the neuron output and cell state independently set in LSTM, and unified them as the output of GRU hidden neural unit. Long-term dependent historical information can be transmitted, and the structure is further simplified. A typical GRU structure is shown in Fig. 5.
The cyclic neuron in the GRU network includes two gate structures. The cell state and output in the LSTM are unified into the output ht in the GRU, so that the GRU has a very concise structure. The calculation process is as follows:
In the formula, ⊗ represents the multiplication operation. ω and b respectively represent the weight and bias in the neuron. The subscript clearly indicates the position of the weight in the network. For example, ωxr represents the weight matrix between the input and reset gates. bg represents the offset vector of the update gate. ht and h̃t respectively represent the output state and candidate output state of the hidden layer neuron at time t. σ is the activation function, and the sigmoid function is selected by default. The output value of the two gate structures is compressed to the range of [0,1], which can represent an activation probability. gt and rt represent the update gate and reset gate respectively.
4.3. Encoder-decoder
Firstly, define the timing attention as
. And according to the time series attention, the input multi-variable data X = (x1, x2, ···, xT) can be updated, where
. Through time series attention, the network can pay more attention to the important information in the input multivariable data. Reduce the adverse effect of interference information on the network, thereby improving the feature extraction ability of the network.
The new GRU layer is used to encode the updated multivariate data, and the hidden state ht of the GRU unit at different times t is obtained. And it is used as the encoded feature matrix:
In order to improve the prediction accuracy of the model, the historical data of the target sequence and the historical data of other influencing factors are separately input into the model. The feature matrix obtained by the feature encoder is fused with the historical data of the target sequence and then decoded for the first time:
Where, ω ∈ R1+m and b̂ ∈ R are the parameters that the network needs to obtain through training. [ŷt−1; ht−1] ∈ R1+m is the layer input after data fusion.
The ŷt−1 obtained through the initial decoding can be used to update the hidden state Ht of the feature decoder at time :
Using GRU units as the non-linear function f2. Ht is updated as follows:
Where, ω′ and b′ are the weights and biases of the network.
For the updated Ht, perform the final decoding to obtain the predicted value Y of the model:
Where, ω0 ∈ Rm and b0 ∈ R are the parameters that the network needs to obtain through training.
4.4. Timing Attention
The timing attention is calculated by the GRU layer. Using the data xt of different influencing factors of the time t of the input data X and the hidden state hk−1 of the GRU unit, the different attention values
of the input data X at different time steps can be constructed:
Where, γe ∈ Rn, ωe ∈ Rn×2T, ζe ∈ Rn×n are the parameters that the network needs to obtain through training. In order to make the sum of attention weights 1, it is necessary to use the Softmax function to obtain the final time series attention value
:
5. Experiment and Analysis
5.1. Experimental Data
The selected research area is Beijing, where air pollution is more representative. The data comes from the national air quality real-time release platform of the China Environmental Monitoring Station. The sample is the hourly concentration data of air pollutants at 35 air quality monitoring stations in Beijing from January 1, 2018 to December 30, 2020. There are six pollutants: PM2.5, SO2, NO2, O3, CO, and PM10. The file format is csv, and the data format is: the first line is the column name (respectively the date, hour and time, data type, and each monitoring site name). Each of the remaining lines is the measured data of a certain pollutant at a certain time, and the data unit is μg/m3. The 35 air quality monitoring sites in Beijing consist of 12 urban environmental assessment points, 11 suburban environmental assessment points, 7 control points and regional points, and 5 traffic pollution monitoring points, as shown in Table 1.
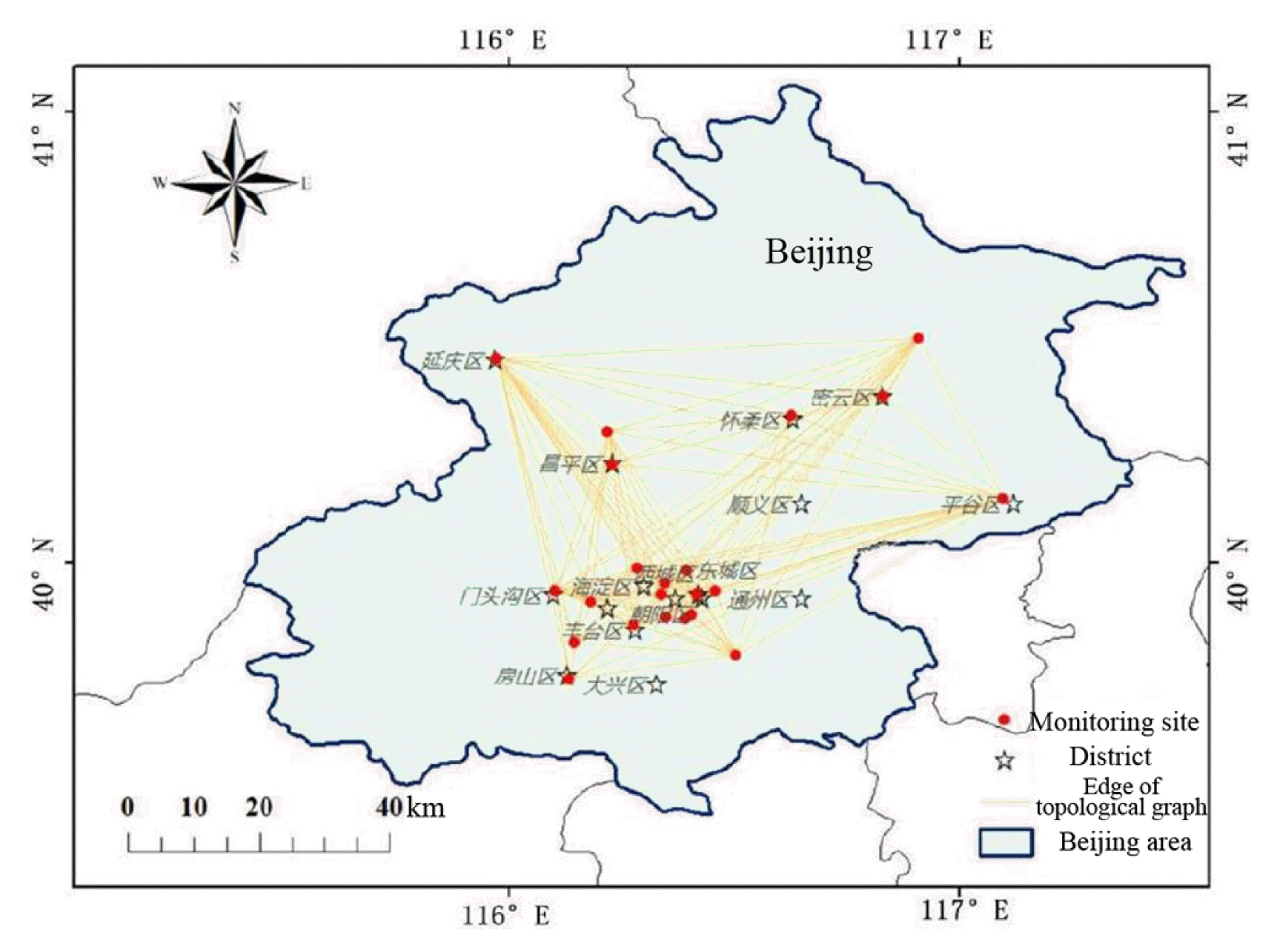
There are six pollutants: PM2.5, SO2, NO2, O3, CO, and PM10. The data missing rates of these six pollutants were 3.12, 6.48, 4.13, 3.24, 3.08 and 32.10%. After removing pollutants with a data missing rate greater than the threshold, some monitoring sites are removed based on the remaining pollutant data missing rate at the monitoring site. If there is no less than one pollutant on the monitoring site with a data missing rate greater than 5%, just remove this monitoring site. In the end, 22 air quality monitoring stations were retained in this article. The spatial distribution of 22 monitoring stations and their spatial topology are shown in Fig. 6. After eliminating pollutants and monitoring stations with serious data loss, 282246 original air quality record data were formed. The 282246 records are arranged with time as the row index and site ID as the column index, and are regular into 12830 rows. The 22 stations in each line are separated by “#”, and the pollutant concentration attribute in each station is separated by “,”. The remaining missing values are completed by time linear interpolation. Finally, 17410 data are divided into 8:1:1 training set, verification set and test set.
5.2. Experimental Settings and Evaluation Index
The model hyperparameters set in the experiment are: The number of training iterations is 1,000, the batch size is 128, the rejection rate is 0.1, the number of GRU hidden layers is 64, and the number of long-term historical data sequences is 8. Adam optimizer is used for training, and mean square error (MSE) is used as the loss function. The overall objective function is as follows:
Where, N is the number of training samples.
Three indicators are used to evaluate the difference between the real value Y̆t of PM2.5 and the predicted value Yt. The mean value of PM2.5 is expressed as Ȳ, which specifically includes:
Among them, RMSE and MAE are used to measure the gap between the actual value and the predicted value. RMSE reflects the sensitivity of the model to larger errors, and MAE reflects the robustness of the model. The smaller the two values, the better the prediction effect. R2 measures the ability of the forecast result to represent the actual data. The larger the value, the better the forecast effect.
5.3. Performance Comparison of Different Time Window Sizes
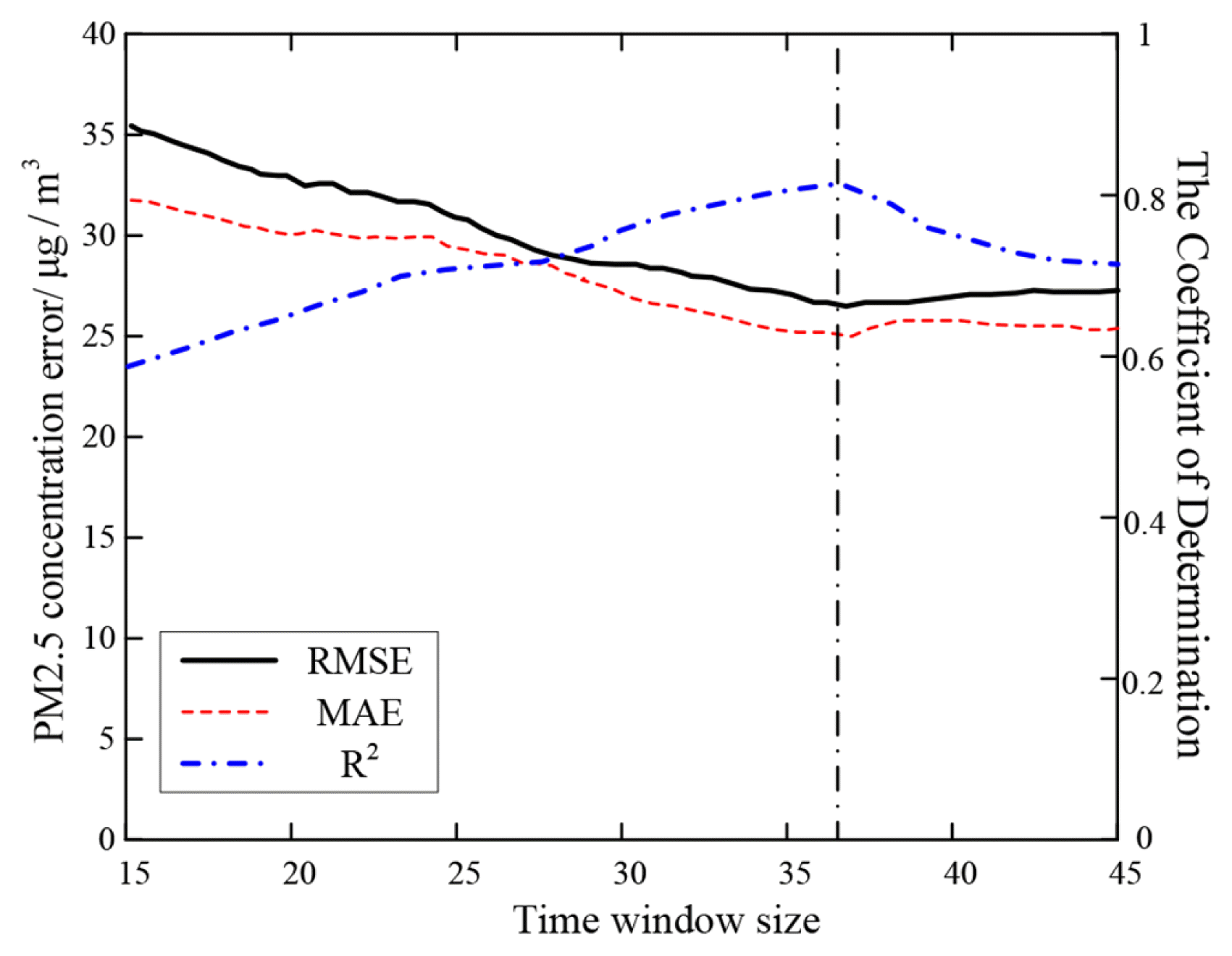
PM2.5 data is affected by a variety of related time series, but changes in each time series value will not immediately affect the PM2.5 concentration value. This means that the variable value at the previous moment has a lagging effect on the PM2.5 concentration value at the next moment. The lag effect may be strong in the short term and weak in the long term. A smaller window size cannot guarantee that the TA-RNN model has enough long-term memory input. The larger window size will increase the input of irrelevant information and increase the unnecessary computational complexity of the model. Therefore, it is necessary to determine the most appropriate window size. The sliding window mechanism is used to construct a corresponding time series sample for each record. In order to set an appropriate historical time window size, select different values from the candidate set of [12, 16, 20, 24, 28, 32, 36, 40, 44] as the window size. The RMSE, MAE, and R2 changes of the proposed model are shown in Fig. 7.
It can be seen from Fig. 7 that when the window size is less than 36, the RMSE and MAE evaluation values decrease as the window size increases, and the R2 evaluation value increases. Because when the window is too small, the historical feature information input to the model is very limited, so the prediction performance is low. When the window gradually increases, the model obtains more and more historical features from the input, which can be used to learn more nonlinearities and dependencies in the sequence and improve the predictive ability. On the other hand, when the window size is greater than 36, the evaluation value of RMSE and MAE increases, the evaluation value of R2 decreases, and then gradually stabilizes. This is because when the window is large enough, it will increase the input of unnecessary information, generate more noise, and thus interfere with the performance of the model. Therefore, the historical time window size is set to 36 in the experiment.
5.4. Anti Interference Ability Detection
Due to the complex reasons for the formation of PM2.5, other meteorological data used in PM2.5 concentration prediction are not necessarily directly related to the PM2.5 concentration change. At this time, it is equivalent to the introduction of interference factors to the network. Therefore, it is necessary to test the anti-interference performance of the network.
Firstly, a set of normal distribution data is randomly generated and added to the model as a kind of meteorological data. Then these models are trained without changing the network parameters. The evaluation results of different models on the data set with interference factors are shown in Table S1.
It can be seen from Table S1 that the three evaluation indexes, R2, RMSE and Mae of TA-RNN are 0.946, 18.01 and 10.38, respectively, which are better than the comparison model. The proposed model uses Gru network to transmit long-term dependence history information, and preprocesses the data such as missing filling, and combines with temporal attention mechanism, which can improve the anti-interference ability of the model.
In addition, the prediction error of different models on the test set with or without interference factors is shown in Fig. S1.
As can be seen from Fig. S1, without adjusting the parameters and structure of the model, the prediction errors of various models on the data sets containing interference factors have increased to varying degrees. Among them, the prediction error of TA-RNN and Ayturan et al. [19] on the test set is the lowest, but the error percentage of the proposed model is relatively low. Even in the presence of interference, the error percentage of PM2.5 concentration is lower than 0.3, which proves that the proposed model has strong anti-interference ability.
5.5. Comparison of Prediction Errors of PM2.5 Concentration Hourly Predicted by Different Models
Taking the haze weather process from November 20 to November 23, 2020 as an example, the hourly concentration prediction curve of PM2.5 with ID 9 under the proposed model and the model in Zhang et al. [14], Ayturan et al. [19] and Yang et al. [22] changes with time are shown in Fig. S2.
It can be seen from Fig. S2 that the trend of the prediction curve of the four models is basically consistent with the actual observation curve. The prediction curve of the model is closest to the actual observation curve, especially near the concentration wave peak. It shows that the model can predict the concentration value of PM2.5 hours better, which plays a very positive role in the short-term prediction of PM2.5 concentration. The prediction curve of the model in Cheng et al. [13] and Goldberg et al. [16] fluctuates in the fitting of PM2.5 concentration trough, and the prediction value of PM2.5 concentration in the next 48 hours deviates greatly, so the prediction effect is not good. The prediction curve of the model in Wang et al. [9] fluctuates most, and the predicted value of PM2.5 concentration peak is larger than the actual observation value, and deviates from the actual observation curve. In contrast, the prediction results of the proposed model are better.
5.6. Comparison of PM2.5 Concentration Prediction Errors of Different Models at Nine Stations
In order to demonstrate the performance of the proposed model, it is compared with Zhang et al. [14], Ayturan et al. [19] and Yang et al. [22] at nine selected sites. The RMSE and MAE error distribution of PM2.5 concentration prediction of the four models is shown in Fig. S3.
It can be seen from Fig. S3 that the RMSE of the proposed model is in the range of [8, 19] and MAE is in the range of [7, 13] for 9 sites. The RMSE of Yang et al. [22] is in the range of [12, 27] and MAE is in the range of [11, 18], while the RMSE and Mae distribution of Ayturan et al. [19] model is similar to that of Yang et al. [22], and the peak value is slightly higher than that of Yang et al. [22]. In Zhang et al. [14], only dynamic Markov model is used to predict PM2.5 concentration. Therefore, the prediction effect in complex environment is poor, with RMSE no less than 20 μg/m3 and Mae no less than 14 μg/m3.
In addition, the overall comparison of PM2.5 concentration prediction of the four models is shown in Table S2.
It can be seen from Table S2 that the RMSE and MAE of the proposed model are 17.93 μg/m3 and 11.52 μg/m3, respectively, which are better than the other three models. In this paper, the model is an encoder decoder structure, and the better performance GRU module and timing attention mechanism are used, so the overall prediction accuracy is better. Yang et al. [22] combined with LSTM and convolutional neural network to achieve PM2.5 concentration at a specific location in the next 24 h, has certain restrictions on time and place, so the generalization ability is poor. In Ayturan et al. [19], the deep learning method was used to predict the pollutant concentration, but the model was simple, so RMSE and MAE increased by 23.48% and 26.20%, respectively compared with the proposed model. Compared with the other three deep learning algorithms, the traditional dynamic Markov algorithm in Zhang et al. [14] has poor overall performance. In a comprehensive way, the prediction effect of the model is the best.
6. Conclusions
Based on the analysis of spatial-temporal correlation of PM2.5 concentration data in Beijing, a TA-RNN prediction model was proposed. The data is encoded by the feature encoder to obtain the intermediate feature, and the intermediate feature and the historical information of PM2.5 concentration are fused into the feature decoder to obtain the predictive value of PM2.5 concentration. The reasonable use of attention mechanism makes the model have a strong ability to identify interference factors and enhance the generalization ability of the model. The results show that when the time window is set to 36, the prediction effect and generalization ability of the model are the best, and the predicted value is the closest to the real value in three days or more. Meanwhile, RMSE and MAE were 17.93 μg/m3 and 11.52 μg/m3, respectively, which were better than other models, and greatly improved the stability and generalization ability of PM2.5 concentration prediction model.
Only several air pollutant concentrations are used as attribute data of each air quality monitoring station, that is, only the correlation between air pollutants is considered, and no other effective information such as meteorology, economy and society is considered. The next step of the study will include more effective information and expand the attribute data of air quality monitoring sites. Consider suggesting a policy that can effectively reduce PM2.5 based on this model, and through this research, analyze the changes in PM2.5 concentration with changes in other air pollutants or meteorological factors.