This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
Recently, the research paradigm has shifted towards prediction, characterization and categorization of droughts for its global impacts on agriculture-based economy. This study aims to parsimoniously forecast the drought phenomena categorized by standardized precipitation index (SPI) for the north-western part of Bangladesh using autoregressive moving average (ARIMA) models. We considered four meteorological stations, namely Bogra, Dinajpur, Ishwardi and Rajshahi which were mostly affected by the droughts. Seasonal effects were most distinct for higher order SPI series with time scales of 12 months and needed to be seasonally differenced. Based on root mean square error (RMSE) and mean absolute error (MAE), the accuracy of the models increased as the order of the SPI series increased over time. There were approximately 60% decrease in RMSE and MAE values for SPI12 series compared to SPI3 series for selected stations. We found as the number of lead times increased the accuracy of the models decreased. A maximum of 6 months lead time was found for SPI12 series at Ishwardi where the fitted model accurately predicted the series. The present study concluded that the researcher should use short term prediction of drought using higher order SPI series for better prediction.
Climate variability and change associated to global warming is already extant on global and regional scale [1]. Changes in the severe climate events particularly severe drought events can have substantial effects on ecosystems, socioeconomic activities, agriculture, and profit from water resources [2]. Drought refers to a prolonged hydro-meteorological event that affects vast regions and causes major non-structural damages. It is originated as a water scarcity situation on account of deficiency of precipitation (less than normal) over a long period of time. Drought is a recurring and the most complex climate phenomenon that always had adversely affected civilization throughout the history of time, due to its potential harmful impacts on economic, environmental, and social sectors. However, despite all, it is often quite less understood than the other natural hazards [3, 4]. Thus, knowledge of drought frequency is recognized as one of the most significant factors in water resources planning and management. High temporal and spatial variability of climate makes Bangladesh as one of the most disaster-prone countries in the world and vulnerable to climate change [5]. The impact of a major drought in Bangladesh can be devastating as about 84% of the 145 million people of Bangladesh are to a great extent involved in agricultural activities, either directly or indirectly [6]. The country experiences average annual rainfall of 1,500 mm in the west to 4,100 mm in the east and almost 80% of rainfall occurs during monsoon. Groundwater irrigation coverage has increased from 6% to 75% in Bangladesh during the period 1980–2000 [7]. Number of rainy days has decreased significantly throughout Southeast Asia [8] and an increased frequency of droughts has been observed in Bangladesh over the recent years [5].
Researchers forecast drought phenomena using both traditional time series techniques and machine learning models. One of the major applications of autoregressive integrated moving average (ARIMA) model is drought forecasting. It is a univariate approach which has gained relative popularity over other models due to its trend detection capability and the complexity as well as constraints of main stream climate models. ARIMA has been used by several researchers and experts in the study of climatology and other geophysical studies [9–13]. A stochastic linear model was developed by Durdu [14] for drought forecasting using standardized precipitation index (SPI) in Turkey. The forecasting capability of the time series models evaluated with the different accuracy measures namely, mean error (ME), root mean square error (RMSE) and mean absolute error (MAE) [15–17]. Belayneh et al. [18] compared the effectiveness of five data driven models for forecasting 6- and 12-months lead time (long term) drought conditions in the Awash River Basin of Ethiopia. They forecasted SPI 12 and SPI 24 employing ARIMA model, artificial neural networks (ANN), and support vector regression (SVR). They also used wavelet transforms to pre-process the inputs for ANN and SVR models to build WA-ANN and WA-SVR models. They compared the performances of all models using RMSE, MAE, and a measure of persistence. The forecast results pointed out that the coupled wavelet neural network (WA-ANN) models performed better than all the other models in this study for forecasting SPI 12 and SPI 24 values over 6- and 12-months lead time in the Awash River Basin of Ethiopia. Myronidis et al. [19] observed negative trends in the SPI drought index using the Mann-Kendall. They measured the correlation between the intensity of drought phenomena and the shallow Mediterranean lake’s water level using the Pearson correlation coefficient. They made a year ahead forecast of future drought conditions by employing a hybrid ARIMA and ANN model. The results suggested that the water level would further drop while the mild drought conditions can be expected in the future. Morid et al. [20] predicted two drought indices including EDI and SPI in Tehran using ANN models. They obtained the best prediction for the 6-months lead time with a value of 0.79 in an area where average annual precipitation varies across different stations from 700 mm to 120 mm. Jalalkamali et al. [21] forecasted drought for the Yazd synoptic station by applying the multilayer perceptron artificial neural network (MLPANN), adaptive neuro-fuzzy inference systems (ANFIS), support vector machine (SVM) model, and the autoregressive integrated moving average (ARIMAX) multi-variate time series. Moreover, they calculated the humidity levels for short-term (3 and 6 months) and long-term (9, 12, 18, and 24 months) periods using the SPI. They chose the 1961–2002 period as the control group and the 2003–2012 period as the experimental group. Based on the results, they revealed that in a 9-months period, the ARIMAX model perform better than the SVM, ANFIS, and MLPANN models. The number of studies related to forecasting the drought phenomena for Bangladesh is sparse. Since the economy of Bangladesh relies on agriculture to a greater extent and drought has deleterious effect on agriculture, it is of utmost importance to model and forecast the drought for Bangladesh.
Hence, this paper adopted SPI approach to quantify and delineate the drought situation in 4 stations of the north-western part of Bangladesh. Hence, the two major objectives of this study include fitting the appropriate time series model for the SPI series of 4-time scales, namely, SPI3, SPI6, SPI9 and SPI12; and evaluating the forecasting power of the fitted models using different accuracy measures. This paper is organized into following sections. Data and methods are outlined in section 2. Section 3 presents the results and discussions and section 4 contains concluding remarks.
2. Data and Methods
2.1. Data
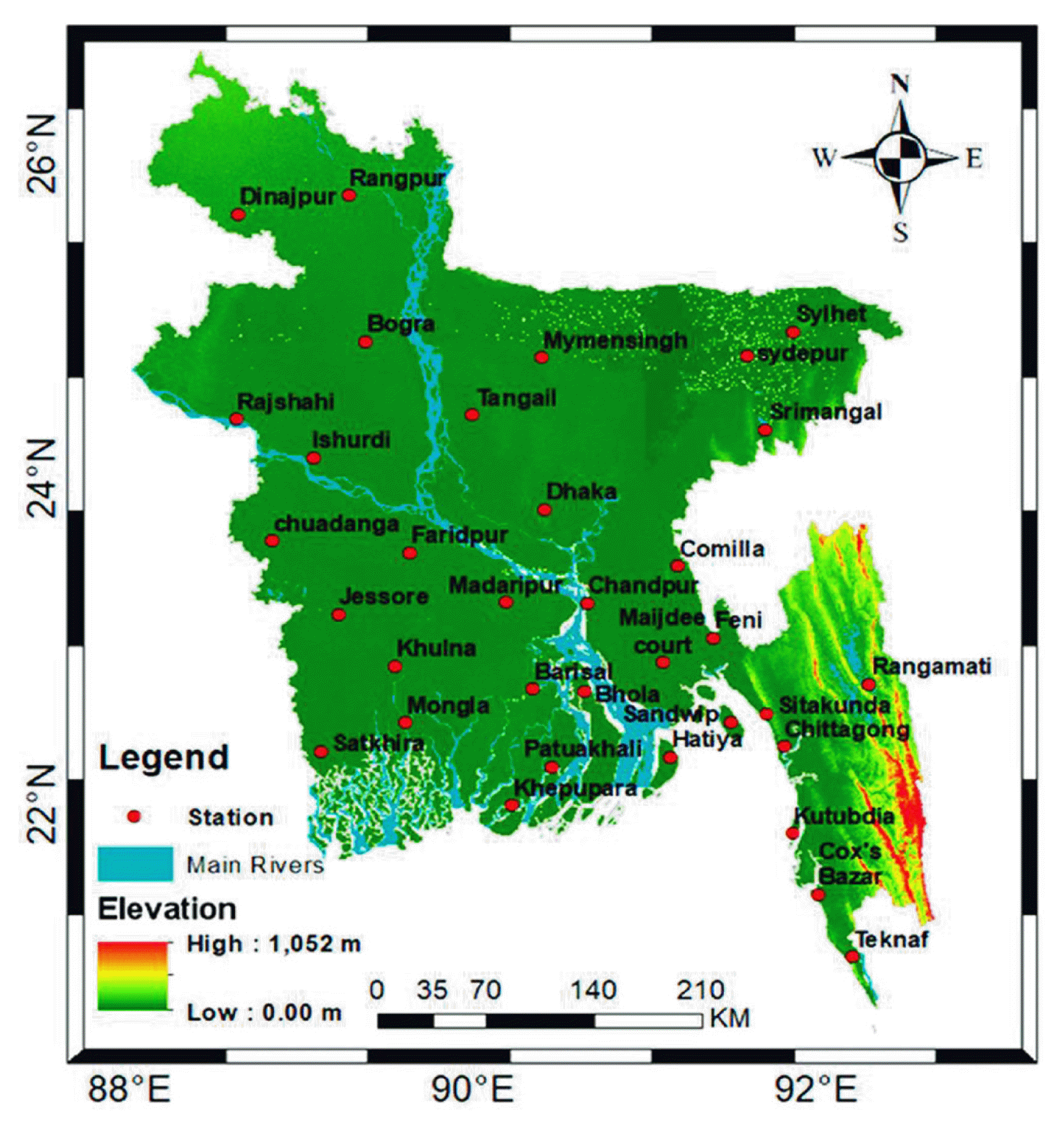
In this study, precipitation data of Bangladesh were obtained from Bangladesh Agricultural Research Council (BARC) online data base. We have selected four stations considering their spatial location in the north-west part of Bangladesh namely Bogra, Dinajpur, Ishwardi and Rajshahi which are mostly affected by droughts. The average annual rainfall of the country varies from 1,329 mm in the northwest to 4,338 mm in the northeast. The gradient of rainfall from west to east is approximately 9 mm/km. The western part of Bangladesh experiences an average areal rainfall of approximately 2,044 mm, which is much lower than that of other parts of the country [22]. All the data series are found to be homogeneous using the von Neumann ratio, Standard Normal Homogeneity Test (SNHT), and the Range test [23]. Fig. 1 shows the map for different meteorological stations of Bangladesh. The data series differs in length for selected stations between 50 to 66 years. The maximum of 66 years monthly precipitation data was obtained for Dinajpur station (1948–2013) and minimum of 50 years for Rajshahi station (1964–2013). So, the data is adequately large enough to fit the seasonal time series models recommended by Hanke et al. [24]. Numerous drought indices have been developed for monitoring and quantification of these kinds of drought [25, 26]. Amid those indices, we have used SPI developed by McKee et al. [27] in this study due to its simplicity and being based solely on the accessible precipitation data.
2.2. Standardized Precipitation Index
In practice, the computation of SPI index in a given year i and a calendar month j, for a time scale k requires the following steps followed by [27, 28]:
Calculation of the collective precipitation series for a time period of interest j in a year i, where each term is the sum of precipitation of k-1 past consecutive months.
Fitting of a cumulative distribution function (usually gamma distribution function) on aggregated monthly precipitation series (e.g., k = 6 months is adopted in this study). The gamma probability density function is defined as,
(1)
where β is a scale parameter; α is a shape parameter, which can be estimated using method of maximum likelihood; and Γ(α) is the gamma function at α. The cumulative probability distribution of observed precipitation event for the given month and time scale can be found with the help of estimated parameters. The cumulative distribution function (CDF) is obtained by integrating Eq. (1), i.e.
(2)
Since two-parameter gamma function is not defined for zero values, and precipitation distribution may contain zeros, a mixed distribution function (zeros and continuous precipitation amount) is employed, and the CDF is given as follows:
(3)
where G(x) is the distribution function estimated for nonzero precipitation, and q is the zero-precipitation probability from the historical time series.
As precipitation is not normally distributed, an equiprobability transformation (Panofsky and Brier, 1958) is carried out from the CDF of mixed distribution to the CDF of the standard normal distribution with zero mean and unit variance, which is given as follows:
(4)
This transformed probability is the SPI. A positive value of SPI indicates that precipitation is above average, and a negative value denotes below average precipitation. A drought period is assumed as a consecutive number of months where SPI values remain below a threshold of −0.8. In this study, drought period has been classified into four categories based on the range of SPI values as listed in Table 1 [29].
Drought length or duration (D) is taken as the number of consecutive intervals (months) where SPI remains below this threshold value. As the drought event is formulated at aggregation of monthly time scale, the minimum duration of drought is 1 month. Drought severity (S) is the cumulative values of SPI within the drought duration. For suitableness, severity of drought event i, Si (i = 1, 2, ...) is taken to be positive, which is given by [27]:
(5)
where SPIi is value of ith period SPI for a D duration drought event.
2.3. Autoregressive Integrated Moving Average (ARIMA) Model
ARIMA models are referred to Box-Jenkins models. An autoregressive model of order p is conventionally classified as AR (p). A moving average model with q terms is classified as MA (q). A combined model that contains p autoregressive terms and q moving average terms is called ARMA (p, q) [30]. If the object series is differenced d times to achieve stationarity, the model is classified as ARIMA (p, d, q), where the symbol “d” signifies “integrated”. A time series Yt is said to follow an ARIMA model if
(6)
where B is the backshift operator (i.e. BYt = Yt– 1), ϕ(B) = (1 – ϕ1B – ϕ2B2–···– ϕpBp) is the autoregressive operator, θ(B) = (1 – θ1B – θ2B2–···– θqBq) is the moving average operator and et is the random error term.
Box et al. [31] proposed a methodology that consists of three phases viz. i) Model identification; ii) Estimation of model parameters; and iii) Diagnostic checking for the appropriateness of identified model. Again, identification comprises four steps, namely, stability in variance, checking the stationarity, obtaining stationarity, and model selection and parameter estimation. The model having minimum AIC value is deemed as the parsimonious model. The AIC [32] is defined as follows-
(7)
ln ML denotes the maximized log-likelihood function; and k is the number of independently adjusted parameters.
2.4. Model accuracy Measures
In time series modeling, it is required to assess the accuracy of the fitted model for further predictions. There are two commonly used accuracy measures: root mean square error (RMSE) and mean absolute error (MAE). Sometimes the mean error (ME) also used for the comparison purpose. The flexibility of these measures lies on the fact that their scales are dependent on the scale of the data and hence are effective in comparing different models across data sets that have same scales [15]. Myronidis et al. [16] and Myronidis et al. [17] discussed briefly different accuracy measures in time series modelling.
Let Yi be the observed values at time point i, for i = 1, 2, ..., n and Ŷι be the respective forecast values by the fitted model. The simple correlation coefficient between observed (Yi) and fitted (Ŷι) values is defined as:
(8)
where all the notations stand for usual meaning. Usually, the values of the coefficients r ranges between −1 to +1. Since here we consider the observed and predicted values of the same variable, so always we will find a non-negative (greater or equal zero) coefficient value. The decision can be made via coefficient value as: higher the value, better the model prediction.
Considering the observed and fitted values, we can define the forecast error as, ei = Yi –Ŷι. Using these notations RMSE can be expressed as follows:
(9)
where n is the sample size. The MAE and ME can be defined respectively as:
(10)
(11)
Traditionally, the RMSE have been popular, largely because of its theoretical relevance in statistical modeling. However, it is more sensitive to outliers than MAE or ME which has led some authors [33, 34] to recommend against its use in forecast accuracy evaluation. Smaller the values of RMSE, MAE or ME, better the accuracy of the prediction.
3. Results and Discussions
In this study, we considered four different SPI series with time scales of 3, 6, 9 and 12 months denoted by SPI3, SPI6, SPI9 and SPI12, respectively. Using the function “auto.arima” under the R package “forecast”, we select appropriate time series model for different SPI series and stations (see Table 2). The final model is selected after stationary checking and based on least AIC value as discussed by Durdu [14].
Fig. 2 shows the plots of observed and fitted values of SPI series using the chosen ARIMA models for all four meteorological stations. The figure, which depicts the difference between the observed and fitted values, helps us to visually decide about the accuracy of the fitted model i.e., smaller the difference implies better the model. The figure depicts that the differences are getting smaller as the order of the SPI series increases. This specifies that the perfection of capturing the patterns by the best fitted ARIMA models considerably increased for higher SPI series which supports the discussion by Han et al. [35].
The correlation coefficients between the actual and predicted SPI values from the ARIMA models are used as an accuracy measure of the fit. Table 3 provides the coefficients for 1–8 months lead-time. It is observed that as the lead-time increases, the coefficient decreases. It indicates that the model accuracy is inversely related with the lead time that has been used for the predictions. Here, blank cells refer to the non-existing correlation coefficients. For a given lead-time, there is a gradual increment in the coefficient values with an increase in the time scale of the SPI series, which implies the direct relation between accuracy and order of the SPI series.
If we consider a model as accurate if it has a correlation of 0.7 or higher, we may conclude that the fitted ARIMA models give accurate predictions for 1-month and up-to 2-months lead-time for the shorter series SPI3 and SPI6 respectively for all four stations under consideration. For higher SPI series SPI9 and SPI12, the accurate prediction is possible for longer lead time with a maximum of 6 months for SPI12 series in Ishurdi station. The change of the series of SPI3 and SPI6 can be predicted with accuracy for one to two months ahead, and for SPI6 and SPI12 maximum of six months ahead for different stations. Therefore, we can conclude that the forecasting capability depends on the number of lead time under consideration and order of the SPI series.
Table 4 shows the values of accuracy measures ME, RMSE and MAE of fitted models for different SPI series and stations. These measures quantify the forecasting power of the fitted models by comparing the observed and fitted SPI values. The ME values of fitted models for different stations is close to zero despite of the order of SPI series, which implies the high accuracy of the fitted models. Considering the values of two other measures, RMSE and MSE are decreased as the order of the SPI series increased. This indicates the accuracy of the fitted models go up as the order of the SPI series increases for different stations. There were approximately 60% decrease in RMSE and MAE values for SPI12 series compared to SPI3 series among all four stations. Han et al. [35] also found the similar results where they used SPI to quantify the classification of drought in the Guanzhong Plain, China. They used correlation, and average percentage errors (APE) as the accuracy measures for the fitted time series models. The conclusion based on APE is the same as we obtain using ME, RMSE and MAE.
3.1. Model Validation
To validate the fitted models, we applied the technique “evaluation on a rolling forecasting origin” discussed by Hyndman and Athanasopoulos [36]. In this procedure, the whole data set is considered as a series of training and test sets. Each test set consisting of a single observation and the corresponding training set consists of observations prior to the test observation. Since it is not possible to obtain a reliable forecast based on a small training set, the earliest observations are not considered as test sets. The forecast accuracy is computed by averaging over the test sets. We compared the root mean square errors obtained from time series cross validation (cRMSE) with the residual root mean square errors (rRMSE).
Table 5 shows the cRMSE and rRMSE values for the fitted models with different SPI series. The values of rRMSE for different SPI series are constantly smaller than the cRMSE. This is due to the “forecasts” that used in rRMSE are based on a model fitted to the entire data set, rather than averaging over the forecasts over test observation. But the closeness between rRMSE and cRMSE indicates the accuracy of the fitted models. Thus, the cross-validation supports the adequacy of the time series models fitted for different SPI series.
4. Conclusions
Drought is one of the major obstacles for the development of an agricultural country, like Bangladesh. For defining and monitoring drought, the meteorologists popularly used a measure based on SPI. This research study shows that there is a seasonal effect mostly in the higher SPI series with time scales 12 months. The predictive power of the fitted models was evaluated considering different accuracy measures, namely ME, RMSE and MAE. Under ME, all the fitted models show better accuracy despite of the order of SPI series and location of the metrological stations. For the other two measures RMSE and MAE, the accuracy of the model increases as the order of the SPI series increases. The correlation between observed and predicted SPI series shows that the forecasting power of the fitted models depends on the number of lead time under consideration and order of the SPI series. Model validation also supports the accuracy of the fitted time series models. Finally, the study recommendation is to use short term prediction with higher order SPI series for the accurate drought identification.
Acknowledgment
We sincerely thank Bangladesh Agricultural Research Council (BARC) for making the data available in public. We also thank the anonymous referees for their helpful comments on a previous draft. Nevertheless, we are solely responsible for errors if there are any.
Notes
Author Contributions
M.S.H.B. (Ph.D. student) performed the statistical analyses, discussed the results, made the concluding remarks, and revised the manuscript. M.M.K. (Ph.D. student) initiated the idea, reviewed literatures, wrote introduction, data, and methods and revised the manuscript.
References
1. IPCC. The Physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report. International Panel on Climate Change. 4:2007;
2. Piao S, Ciais P, Huang Y, et al. The impacts of climate change on water resources and agriculture in China. Nature. 2010;467:43–51.
3. Kao SC, Govindaraju RS. A copula-based joint deficit index for droughts. J Hydrol. 2010;380:121–134.
4. Modarres R. Streamflow Drought Time Series Forecasting. Stoch Environ Res Risk Assess. 2006;21:223–233.
5. Shahid S, Behrawan H. Drought risk assessment in the western part of Bangladesh. Nat Hazards. 2008;46:391–413.
6. Mainuddin K, Rahman A, Islam N, Quasem S. Planning and costing agriculture’s adaptation to climate change in the salinity-prone cropping system of Bangladesh. International Institute for Environment and Development (IIED); London, UK: 2011.
7. Parvin L, Rahman MW. Impact of irrigation on food security in Bangladesh for the past three decades. J Water Resour Prot. 2009;3:216–225.
8. Endo N, Matsumoto J, Lwin T. Trends in precipitation extremes over Southeast Asia. Sola. 2009;5:168–171.
9. Hipel KW, McLeod AI, Lennox WC. Advances in Box-Jenkins modeling: 1. Model construction. Water Resour Res. 1977;13:567–575.
10. Salas JD, Smith RA. Physical basis of stochastic models of annual flows. Water Resour Res. 1981;17:428–430.
11. Elek P, Márkus L. A long range dependent model with nonlinear innovations for simulating daily river flows. N Hazard Earth Sys Sci. 2004;4:277–283.
12. Xu T, Wu J, Wu ZS, Li Q. Long-term sunspot number prediction based on EMD analysis and AR model. Chin J Astron Astrophys. 2008;8:337–342.
13. Chattopadhyay S, Jhajharia D, Chattopadhyay G. Univariate modelling of monthly maximum temperature time series over northeast India: neural network versus Yule–Walker equation based approach. Meteorol Appl. 2011;18:70–82.
14. Durdu ÖF. Application of linear stochastic models for drought forecasting in the Büyük Menderes river basin, western Turkey. Stoch Environ Res Risk Assess. 2010;24:1145–1162.
15. Hyndman RJ, Koehler AB. Another look at measures of forecast accuracy. Int J forecast. 2006;22:679–688.
16. Myronidis D, Fotakis D, Ioannou K, Sgouropoulou K. Comparison of ten notable meteorological drought indices on tracking the effect of drought on streamflow. Hydrol Sci J. 2018;63:2005–2019.
17. Myronidis D, Ioannou K, Fotakis D, Dörflinger G. Streamflow and hydrological drought trend analysis and forecasting in Cyprus. Water Resour Manag. 2018;32:1759–1776.
18. Belayneh A, Adamowski J, Khalil B, Ozga-Zielinski B. Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J Hydrol. 2014;508:418–429.
19. Myronidis D, Stathis D, Ioannou K, Fotakis D. An integration of statistics temporal methods to track the effect of drought in a shallow Mediterranean Lake. Water Resour Manage. 2012;26:4587–4605.
20. Morid S, Smakhtin V, Bagherzadeh K. Drought forecasting using artificial neural networks and time series of drought indices. Int J Climatol. 2007;27:2103–2111.
21. Jalalkamali A, Moradi M, Moradi N. Application of several artificial intelligence models and ARIMAX model for forecasting drought using the Standardized Precipitation Index. Int J Environ Sci Technol. 2015;12:1201–1210.
22. Khan RH, Islam M. Comparative Study of the Changes in Climatic Condition and Seasonal Drought in North-Western Part of Bangladesh. J Asiat Soc. 2018;30(2)195–210.
23. Shahid S, Wang XJ, Harun S. Unidirectional trends in rainfall and temperature of Bangladesh. In : IAHS-AISH proceedings and reports; United Kingdom. 2014.
24. Hanke JE, Reitsch AG, Wichern DW. Business forecasting. Upper Saddle River. New Jersey: Prentice Hall; 2001.
25. Heim RR. A review of twentieth-century drought indices used in the United States. Bull Amer Meteor Soc. 2002;83:1149–1165.
26. Keyantash J, Dracup JA. The quantification of drought: an evaluation of drought indices. Bull Amer Meteor Soc. 2002;83:1167–1180.
27. McKee TB, Doesken NJ, Kleist J. The relationship of drought frequency and duration to time scales. In : Proceedings of the 8th Conference on Applied Climatology; Boston. 1993.
28. Wu H, Svoboda MD, Hayes MJ, Wilhite DA, Wen F. Appropriate application of the standardized precipitation index in arid locations and dry seasons. Int J Climatol. 2007;27:65–79.
29. Svoboda M, LeComte D, Hayes M, et al. The drought monitor. Bull Amer Meteor Soc. 2002;83:1181–1190.
34. Armstrong JS, Collopy F. Error measures for generalizing about forecasting methods: Empirical comparisons. Int J Forecast. 1992;8:69–80.
35. Han P, Wang P, Tian M, et al. Application of the ARIMA models in drought forecasting using the standardized precipitation index. In : International Conference on Computer and Computing Technologies in Agriculture; Berlin, Heidelberg. 2012.
36. Hyndman RJ, Athanasopoulos G. Forecasting: principles and practice. OTexts; 2018.
Fig. 1
Map of meteorological stations of Bangladesh.
Fig. 2
Plots of observed and fitted SPI series for all the four meteorological stations of Bangladesh. (a) Bogra, (b) Dinajpur, (c) Ishurdi, (d) Rajshahi.
Table 1
Drought Categories According to SPI Values
SPI
Category
−0.8 to −1.2
Moderate drought
−1.3 to −1.5
Severe drought
−1.6 to −1.9
Extreme drought
≤ −2.00
Exceptional drought
Table 2
The Best Fitted Time Series Models for Different SPI Series and Stations
Station
Selected Models
SPI3
SPI6
SPI9
SPI12
Bogra
ARIMA(1,0,3)
ARIMA(0,0,5)
ARIMA(3,0,2)
ARIMA(1,0,0) (2,0,2)12
Dinajpur
ARIMA(1,0,4)
ARIMA(0,0,5)
ARIMA(3,0,2)
ARIMA(1,0,0) (0,0,1)12
Ishurdi
ARIMA(0,0,2) (1,0,0)3
ARIMA(0,0,5)
ARIMA(3,0,2)
ARIMA(1,0,1) (2,0,1)12
Rajshahi
ARIMA(1,0,2) (1,0,0)3
ARIMA(0,0,5)
ARIMA(1,0,0)(1,0,1)9
ARIMA(1,0,0) (1,0,1)12
Table 3
Correlation Coefficients Between Observed and Fitted SPI Series at Different Lead-time for Different Stations
Station
SPI Series
Lead time in months
1
2
3
4
5
6
7
8
Bogra
SPI3
0.940
0.437
0.023
SPI6
0.956
0.740
0.570
0.404
0.243
0.037
SPI9
0.989
0.827
0.684
0.585
0.459
0.360
0.282
0.160
SPI12
0.966
0.848
0.739
0.628
0.517
0.415
0.311
0.207
Dinajpur
SPI3
0.941
0.603
0.250
SPI6
0.960
0.782
0.656
0.542
0.416
0.229
SPI9
0.993
0.887
0.777
0.708
0.630
0.544
0.484
0.387
SPI12
0.976
0.899
0.815
0.715
0.607
0.502
0.395
0.287
Ishurdi
SPI3
0.915
0.459
0.025
SPI6
0.949
0.737
0.574
0.416
0.282
0.106
SPI9
0.990
0.857
0.765
0.671
0.597
0.523
0.435
0.367
SPI12
0.987
0.933
0.880
0.830
0.778
0.721
0.662
0.605
Rajshahi
SPI3
0.937
0.481
0.088
SPI6
0.957
0.736
0.575
0.443
0.270
0.063
SPI9
0.990
0.852
0.738
0.632
0.523
0.417
0.314
0.209
SPI12
0.959
0.852
0.748
0.632
0.508
0.389
0.276
0.169
Table 4
Results of Different Accuracy Measures for Different SPI Series and Stations.
Station
SPI Series
ME
RMSE
MAE
Bogra
SPI3
0.000
0.731
0.568
SPI6
−0.001
0.599
0.445
SPI9
0.001
0.477
0.399
SPI12
0.001
0.312
0.204
Dinajpur
SPI3
−0.002
0.688
0.509
SPI6
0.000
0.563
0.404
SPI9
−0.001
0.444
0.293
SPI12
0.000
0.270
0.164
Ishurdi
SPI3
0.001
0.726
0.544
SPI6
0.003
0.566
0.410
SPI9
0.002
0.434
0.299
SPI12
0.002
0.284
0.182
Rajshahi
SPI3
0.001
0.704
0.558
SPI6
0.000
0.613
0.454
SPI9
0.002
0.484
0.335
SPI12
−0.001
0.301
0.194
Table 5
Cross-validation of The Fitted Time Series Models for Different Meteorological Stations of Bangladesh